O protocolo OSPF é cobrado tanto no CCNA atual, seja na prova CCNA 200-125 como na prova ICND-2 200-105, assim como no novo CCNA 200-301 que ainda não foi lançado.
Portanto se você estudar esse assunto hoje e não conseguir fazer a prova atual, pois estou escrevendo esse artigo antes da virada de fevereiro de 2020, esse assunto continuará caindo na prova nova!
No CCNA normalmente é cobrado que o aluno consiga identificar e resolver problemas (processo de troubleshooting) nos seguintes tipos de problemas:
Problemas básicos de camadas 1, 2 e 3
Configurações erradas
Falta de configurações
Portanto nesse artigo eu vou falar sobre esses três tipos de problemas e um quarto mais específico que é sobre a formação de adjacências.
Vamos a cada um deles a seguir!
Problemas Básicos de Camadas 1, 2 e 3 do Modelo OSI
Muitas vezes o OSPF não forma uma adjacência porque temos cabos rompidos ou tipos de cabos errados nas conexões (por exemplo, deveria ser um cabo cross e foi utilizado um direto).
Na camada de enlace em interfaces seriais DCE falta o comando clock rate ou o tipo de protocolo em uma das pontas está errado (encapsulation) e na camada de rede o IP/máscara das interfaces pode estar errado.
Se ambas as interfaces vizinhas diretamente conectadas não estiverem na mesma rede IP o OSPF não sobe.
Configurações Erradas
Redes anunciadas erradas no comando network, tanto a rede como a máscara curinga ou a própria área são os problemas mais cobrados nas questões do CCNA.
Quando utilizamos uma única área é obrigatório que todas as redes estejam configuradas na área zero que é chamada de backbone.
Além disso, os temporizadores de Hello e Dead devem ser iguais em ambos os roteadores para que a adjacência possa ser formada.
Lembre-se que tudo isso deve ser estudado durante sua preparação para o CCNA!
Falta de configurações
Interfaces não selecionadas ou faltantes no comando network são os problemas mais comuns que podem ser cobrados em questões ou simulados para o CCNA.
Os comandos show relacionados ao OSPF devem ser estudados e detalhados durante a sua preparação.
Podem haver questões solicitando a análise de um comando show e solicitando que informações sejam fornecidas, por exemplo, com a saída de um show running-config parcial e um show ip interface brief a questão pode pedir as interfaces que farão parte do processo OSPF em questão.
Problemas com a Formação de Adjacências no OSPF
O problema de formação de adjacência no OSPF também é um assunto recorrente em provas do CCNA, por isso mesmo detalhamos muito bem esse assunto em nosso cursos preparatório, mais especificamente hoje enquanto escrevo o artigo no curso CCNA ICND-2.
Lembre-se que o processo do OSPF inicia com a troca de hellos e a formação da vizinhança, chamada de adjacência.
Para que isso ocorra já estudamos que alguns parâmetros básicos devem ser configurados da mesma maneira em ambos os vizinhos.
A seguir
vamos ver os principais problemas que podem ocorrer e os comandos que são
indicados para resolvê-los.
Os roteadores devem estar na mesma sub-rede -> utilizar os comandos show interfaces
e debug ip ospf hello.
Caso configurada autenticação, ambos os vizinhos devem passar nessa fase
(autenticação mútua e bidirecional) -> utilizar os comandos show ip ospf
interface e debug ip ospf adj.
Temporizadores de hello e dead devem ser iguais -> utilizar os comandos show
ip ospf interface e debug ip ospf hello.
As interfaces vizinhas devem estar na mesma área -> utilizar os comandos show
ip ospf interface brief e debug ip ospf adj.
O RID deve ser único na rede -> utilizar o comando show ip ospf.
Lembre-se
que se a vizinhança foi formada e houve o fechamento da adjacência os
roteadores devem ser mostrados no comando “show
ip ospf neighbor” com o estado de Full, com exceção do estado da vizinhança
entre roteadores DROTHER que ficam em 2-way, eles ficam em Full apenas com o DR
e BDR.
Outro problema que pode impedir o estabelecimento de uma vizinhança é o comando “passive-interface” declarado de maneira errada ou a falta do “no passive-interface” para uma nova interface inserida no OSPF quando utilizamos o “passive-interface default”.
Lembre-se que a interface passiva não pode formar adjacência devido ao hello ser ignorado quando ela está nesse estado, portanto sua rede é anunciada no processo do OSPF, porém a interface não é capaz de formar adjacência.
O comando show que pode ajudar nesse tipo de situação, além do show running-config, é o show ip ospf interface brief.
Com esse comando podemos verificar todas as interfaces que estão inseridas no processo do OSPF e depois no show running-config identificar quais estão passivas.
Onde Eu Posso Estudar Mais Sobre OSPF para CCNA na DlteC
Essa é uma ótima pergunta, pois enquanto não lançarmos o curso específico para o CCNA 200-301 você pode estudar OSPF no curso CCNA ICND-2.
Nosso preparatório atual para o CCNA 200-125 é dividido em dois cursos, e o OSPF está no segundo módulo.
Outra forma de estudar OSPF conosco é com a trilha de Protocolos Roteamento IP, onde temos cursos que abordam desde a teoria até a prática avançada do protocolo OSPF. Veja os cursos abaixo:
Essa trilha de cursos vai bem além do OSPF, porém pode também ser utilizada apenas para seu aprendizado, porém o primeiro curso sobre Roteamento IP e RIP é recomendado antes do estudo dos próximos cursos.
Com isso terminamos mais um artigo e espero que tenha sido útil!
Não esqueça de deixar sua mensagem, crítica, sugestão ou até mesmo elogio no campo logo abaixo desse artigo!
Olá amigos, fãs, alunos e seguidores do nosso Blog! Enfim saíram os valores das novas certificações Cisco após a virada de 24 de fevereiro de 2020!
Eu mesmo entrei essa semana no site da Pearson e confirmei que as novas provas já estão listadas no catálogo.
Se você não sabe, não leu ou está por fora: TUDO MUDA EM 2020 NAS CERTIFICAÇÕES CISCO!
Resumindo o que vai rolar a partir de 24 de fevereiro de 2020 nas certificações Cisco:
Certificações CCT continuam a existir
CCENT “morre”
CCNAs atuais dão lugar ao novo CCNA 200-301 (que será 70% do CCNA R&S atual)
No início dos esclarecimentos das novidades o CCNA Cyber Ops não estava mais listado para após a virada de 2020, porém agora aparece no site como “mais um sobrevivente” às alterações
Nova carreira criada para a área de Devnet (Software)
Carreira de R&S (Routing and Switching) passa a ser chamada de Enterprise Infrastructure
CCNPs passam a ser compostos de DUAS provas: Core+Concentration
Prova CORE dos CCNPs começam a valer como o atual CCIE WrittenExam
O CCT (Cisco Certified Technician) não teve alteração até o momento que escrevi o artigo e continuam custando 125 dólares americanos.
Ambos CCNAs (200-301 e Devnet) terão um valor de investimento de US$255 (duzentos e cinquenta e cinco dólares americanos).
O CCNA 200-301não terá mais versão em duas provas como o atual CCNA R&S, o qual pode ser realizado através do exame 200-125 (CCNAX) ou em dois exames: 100-105 (ICND1/CCENT) + 200-105 (ICND2).
O CCNA Cyber Ops continua em duas provas (210-250: Understanding Cisco Cybersecurity Fundamentals + 210-255: Implementing Cisco Cybersecurity Operations) , cada uma com o valor de 255 dólares e totalizando 510 dólares, portanto o dobro que os outros dois CCNAs.
As provas do CCNP terão um custo mínimo de US$700 (setecentos dólares americanos), pois as provas de CORE custarão 400 dólares e cada prova de Concentration custará 300 dólares americanos.
Houve uma redução no custo total para obtenção das certificações, tanto para o nível Associate (CCNA) como para o Professional (CCNP), assim como prometido pela própria Cisco.
Por exemplo, o CCNP R&S são três provas (ROUTE+SWITCH+TSHOOT) que atualmente tem um valor de 300 dólares cada, portanto para o novo CCNP teremos uma economia de 200 dólares.
Mas é claro, para você ficar “fera” na trilha Enterprise Infrastructure você precisa gastar bem mais que a versão anterior que tinham apenas três provas, pois agora TODAS as trilhas do nível profissional oferecem pelo menos seis opções de especialização.
Mas uma dica: mesmo com essas mudanças em valores ainda vale a pena PASSAR TANTO NO CCNA COMO NO CCNP ANTES DA VIRADA.
Se você está estudando: NÃO PARE!
A pior opção é parar e esperar, pois nossa área não para de crescer e se desenvolver, por isso mesmo PARAr NÃO É UMA OPÇÃO agora.
E se você está se perguntando se vamos atualizar nosso portal para as novas certificações Cisco a resposta é SIM. Em breve anunciaremos mais sobre o assunto, porém nessa fase final de mudança de provas nossos alunos estão muito focados em garantir a certificação antes da virada em fevereiro de 2020, por isso mesmo temos que dar uma atenção especial para isso, concorda?
Mas é claro que vamos ter no mínimo o CCNA 200-301 e o CCNP Enterprise atualizados em nosso Portal… promessa é dívida!
Então é isso aí, ficamos por aqui e espero que você tenha gostado das novidades!
Deixe seu comentário que eu pessoalmente gosto de ler e responder!
Olá amigos, leitores, fãs e alunos da DlteC! Hoje vamos falar sobre o Dual Stack ou Pilha Dupla em ambientes que possuem os protocolos IPv4 e IPv6 rodando simultaneamente.
A pilha dupla, como o próprio nome diz, é ter ambos os protocolos IPv4 e IPv6 configurados tanto nas interfaces dos dispositivos de rede como nos hosts e servidores, ou seja, em todos os nós e endpoints da rede.
Dessa maneira, quando o host for se comunicar com outros hosts IPv4 ele utiliza a pilha do protocolo IP versão 4, porém quando for conversar com um host ou servidor IPv6 utilizará a pilha referente ao protocolo IP versão 6.
Note que nessa técnica não há nenhum tipo de tradução ou interconexão entre os protocolos, ou seja, os fluxos IPv4 e IPv6 são separados e o computador usa um ou outro.
Outro ponto importante é que não há comunicação entre o protocolo IPv6 e IPv4, ou seja, a camada de transporte escolhe enviar seu fluxo por um ou por outro de acordo com o que a aplicação for utilizar.
Por exemplo, você digitou em um navegador o endereço IPv6 de um servidor (http://2002:13fa:0:4::2 – exemplo hipotético) aqui a pilha do protocolo IPv6 será usada para criar a conexão entre o computador e o servidor.
Agora, se no exemplo anterior o usuário digitasse “http://10.0.0.10”, a pilha de protocolos TCP/IP utilizaria o IPv4 para enviar os pacotes entre o cliente e o servidor.
Inclusive esses dois endereços poderia pertencer ao mesmo servidor sem problema algum.
Portanto, em uma rede poderemos encontrar dispositivos somente Ipv4, com pilha dupla ou somente IPv6, sendo que o único que irá conseguir falar com dispositivos remotos tanto com IPv4 e IPv6 será o que possui a pilha dupla configurada.
Veja a próxima figura mostrando na prática que um host com pilha dupla possui um endereço IPv4 e um IPv6 configurado na mesma interface de rede.
Na implementação de uma pilha dupla é importante lembrar que
as configurações dos recursos de rede para o IPv4 e IPv6 serão independentes em
diversos aspectos, seguem alguns pontos importantes a serem considerados
abaixo:
Informações nos servidores DNS autoritativos,
pois as entradas para os servidores IPv6 no DNS possuem necessidades de
configuração específica;
Protocolos de roteamento, pois os roteadores
deverão ser configurados para rotear as redes IPv6, isto não é automático;
Firewalls, pois agora serão necessárias regras
de filtragem baseadas também no fluxo IPv6, sendo que o mesmo vale para os IPSs
e IDSs;
Gerenciamento das redes, pois o uso do SNMP
exige que os gerenciadores e as MIBs tenham suporte ao IPv6 e provavelmente
configurações específicas serão necessárias.
Espero que possa ter ajudado a você compreender melhor esse assunto e conto com sua ajuda para compartilhar nosso artigo em suas redes sociais, assim como grupos!
Mais uma vez agradeço sua visita e até uma próxima.
Ah, se tiver dúvidas, comentários ou simplesmente quiser elogiar nossa trabalho utilize o campo de comentários que fica no final dessa página!
Olá amigos, leitores, fãs e alunos da DlteC do Brasil!!! Hoje vamos falar sobre um assunto muito legal e pouco dominado pela galera de Infra de TI: Switch Stacking.
Portanto leia com atenção porque esse tipo de assunto pode te ajudar a se destacar na multidão! #Ficaadica!
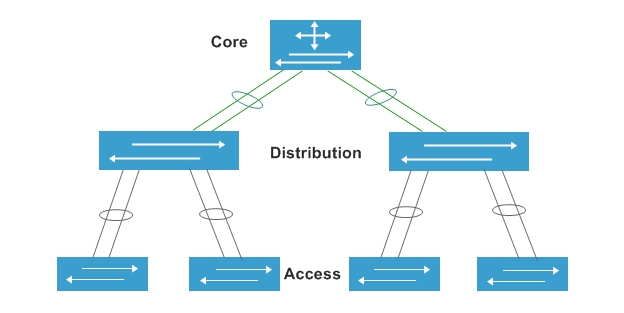
Normalmente os switches de acesso são independentes e se você necessita diversos switches em um mesmo ambiente é preciso conectar links entre eles, por exemplo, trunks via Etherchannel com duas portas entre cada switch.
Porém essa conexão em cascata ocupa cabos que poderiam ser
utilizados para uplink e até conectar mais hosts.
Por exemplo, se você conecta cada switch de acesso ao switch de distribuição com dois cabos e tem 10 switches de acesso, precisaria um total de 20 portas no switch de distribuição para conectá-los, certo?
E se você pudesse empilhar oito desses switches e conectar dois cabos para a distribuição? Isso com certeza daria uma economia considerável ao projeto, concorda?
Para resolver esse tipo de situação a Cisco disponibiliza as tecnologias StackWise e StackWise Plus, permitindo que vários switches sejam “empilhados” e atuem como um só dispositivo.
A feature de StackWise está disponível nos switches modelos Catalyst 3750-E, 3750-X e 3850.
Além disso, existem outras opções de empilhamento como o FlexStack e FlexStackPlus, as quais estão disponíveis nas linhas 2960-S, 2960-X e 2960-XR.
Na prática, os switches empilháveis possuem entradas especiais para conexão dos cabos de empilhamento (stacking cables), os quais são conectados formando um loop (daisy-chain).
Por exemplo, para conectar 4 switches começamos conectando a porta de stack 2 do primeiro switch com porta de stack 1 do segundo, depois porta 2 do segundo com porta 1 do terceiro, na sequência porta 2 do terceiro com a porta 1 do quarto e fechando o loop porta 2 do quarto com a porta 1 do primeiro.
Veja foto a seguir com o esquema de conexão.
Obs.: Os cabos de stacking não acompanham o chassi do
switch!
Quando conectados corretamente, os cabos formam um anel que
possibilita que os switches trabalhem com uma taxa de 32Gbps full-duplex (fluxo
de tráfego bidirecional total entre dois caminhos lógicos counter-rotating),
porém se uma das conexões (cabos de stacking) for rompida a largura de é
reduzida em 50% fazendo com que a pilha passe a operar com 16Gbps.
Principais vantagens do StackWise:
Possibilidade de empilhar até 9 switches em um
mesmo stack, por exemplo, com switches de 48 portas temos 432 portas em uma só
pilha lógica de switches.
Você pode abrir o loop para inserir ou retirar switches
sem que os demais parem de funcionar, tanto para manutenções como changes na
topologia.
Não é preciso fazer nenhuma configuração para
inserção de um novo switch na pilha.
A pilha vai funcionar como um único dispositivo,
tendo apenas um IP de gerenciamento único para todos os switches da pilha e
sendo configurada a partir do switch definido como “mestre”.
Portas de diferentes switches configurados em
uma pilha podem ter suas interfaces configuradas em um link chamado Multichassis EtherChannels (MECs).
Quando os switches precisam enviar quadros entre
si eles utilizam o cabo de stacking, ou seja, ao invés de trocar quadros entre
portas da maneira convencional é como se os cabos de stacking fossem uma
extensão do backplane dos switches.
Elimina o problema de escalabilidade do diâmetro
do protocolo Spanning Tree.
A maior vantagem do switch stacking é reduzir a complexidade de administração, pois a pilha para o gerenciamento acaba sendo como um switch só para o gerenciamento.
Com isso eu termino o artigo e espero que tenha sido útil para você!
Nos ajude compartilhando esse artigo com seus colegas, redes sociais e grupos. Marque a gente com uma hashtag: #dltec, assim podemos saber que você está nos ajudando a compartilhar conhecimento na Internet.
E se você tiver uma dúvida, sugestão ou quiser deixar um elogio tem um campo no final do artigo para seus comentários!
Olá amigos, fãs, leitores e alunos da DlteC!!! Hoje vou mostrar um assunto que pode fazer parte do CCNA, tanto na versão atual como para o 200-301 que são as opções de Debug no OSPF.
O protocolo de roteamento OSPF ou Open Shortest Path First é um protocolo de roteamento dinâmico, classificado como IGP (Interior Gateway Protocol) responsável por determinar rotas para que os roteadores encaminhem os pacotes de rede pelo melhor caminho possível.
E para quem vai fazer uma prova de certificação Cisco da área de Roteamento e Switching, que será a partir de 2020 chamada de Enterprise, é necessário saber a teoria do OSPF, como configurá-lo e também como realizar o troubleshooting utilizando comandos show e debug.
Normalmente os debugs são cobrados em questões de múltipla escolha, pois é difícil simular uma questão com debug.
Portanto temos dois cenários:
Você precisa aprender a utilizar os debugs na sua vida prática, porém deve saber que não dá para sair dando debug “a torto e a direito”, pois você pode parar o roteador e a sua rede.
Você deve saber quando usar caba um deles e a sintaxe correta para fazer sua prova de certificação.
Com o OSPF temos as seguintes opções no comando debug ospf (dependendo da versão de Cisco IOS pode variar):
Para o ICND-2, CCNA 200-125 ou CCNA 200-301 eu preciso saber cada um deles? Não… Os mais relevantes para essas provas são:
debug ip
ospf events: Mostra todas as mensagens para cada evento ou ação tomada pelo
OSPF incluindo o recebimento de mensagens.
debug ip
ospf packet: Mostra as mensagens do OSPF com a descrição do conteúdo de
todos os pacotes.
debug ip
ospf hello: Mostra a mensagens de Hellos e suas falhas. Utilizado para
verificar problemas de formação de adjacência.
debug ip
ospf adj: Mostra eventos relacionados especificamente à formação e
manutenção de vizinhança ou adjacência.
Exemplo de questão sobre debug com OSPF.
Pergunta: Como podemos verificar no OSPF a troca de informações relativas à formação de adjacências no momento que elas acontecem via Cisco CLI? Escolha uma alternativa abaixo.
debug ospf adj
debug ip events
debug ospf packet
debug ip ospf adj
debug ip ospf hello
Pense um pouco e escolha a sua resposta, apenas uma está correta.
Bem, a resposta certa é a “4”.
Muitos podem ter ido na pressa e escolhido a resposta “1”, porém ela tem um detalhe errado, isso chamamos durante o curso de “pegadinha do malandro” (rsrs).
Esse é um exemplo de como você deve estar bem preparado para enfrentar uma prova de certificação e não subestimar o poder do examinador.
Durante nossos cursos damos todas as dicas necessárias para que nossos alunos mantenham nosso alto índice de aprovação de primeira!
Então chegamos ao final de mais um artigo e espero que tenha sido útil!
Peço sua ajuda para compartilhar nosso artigo com seus amigos, grupos e redes sociais, assim vamos colaborando com a comunidade da área de Redes e Infraestrutura de TI para melhorarmos cada vez mais nossos profissionais!
Obrigado e até uma próxima!
Ah, quase esqueci… se você tiver uma dúvida, sugestão ou elogio utilize o campo de comentários para deixar sua mensagem!
Eu vou começar fazendo uma pergunta: “Sua Rede Utiliza Algum dos Protocolos de Roteamento IP? Seja para IPv4 ou IPv6?”
Mesmo que você acredite que não precisa aprender tal assunto, por exemplo, por ter uma rede com apenas uma saída de Internet configurada via rota estática, saiba que a longo prazo (se você pensa em ter uma carreira próspera) esse conhecimento pode fazer a diferença em sua vida profissional na área de Infra de TI e Redes.
Pois ninguém nasceu enraizado…
… e crescer como pessoa e profissional é quase que um objetivo comum a toda humanidade, por isso mesmo temos que estar preparados para desafios maiores.
E no que saber o que é e quando utilizar os principais protocolos de roteamento IP vai me ajudar nesse crescimento?
SIMPLES: se a vaga requer conhecimentos desse tipo é porque ela é média, grande ou está em fase de crescimento… Portanto ótimas oportunidades te aguardam nesse ambiente! E se você já está nessa realidade profissional, conhecimentos adicionais podem garantir crescimento e promoções.
Além disso, esse conhecimento é cobrado em diversas provas de certificação de vários fabricantes, assim como em concursos públicos da área de Infraestrutura de Rede!
Portando preste bem atenção, anote se for possível e saia na frente!
Qual a Função de dos Protocolos de Roteamento IP
Para que os dispositivos de uma rede possam se comunicar entre as diferentes redes em uma Intranet ou na Internet um dispositivo de camada 3 (Rede ou Internet) deve fazer o roteamento dos pacotes.
Quem faz essa função são Roteadores e Switches Layer-3, ou seja, eles tem a função encaminhar os pacotes recebidos em uma interface para outra interface de saída que “conheça” a rede de destino para qual o pacote está sendo enviado.
Esse processo pode ser chamado também de “comutação” ou “chaveamento” em algumas bibliografias, pois o pacote é comutado ou chaveado para uma interface de saída.
Essa análise sobre as redes que um roteador ou até mesmo um terminal (endpoint) tem conhecimento é realizada através da consulta à “tabela de roteamento” IP de cada dispositivo.
Portanto, nos equipamentos que atuam na camada 3 do modelo OSI (como por exemplo, roteadores, switches camada 3 e até mesmo os computadores) existe uma tabela que contém as redes que cada dispositivo conhece, as entradas nessa tabela chamamos de “rotas”.
Uma rota deve conter pelo menos três informações básicas (podendo ter mais):
Rede de destino
Máscara ou prefixo
Interface ou endereço IP de saída, a qual tem alcance à rede de destino
Basicamente existem três maneiras de realizar o roteamento, através de:
Roteamento estático
Rotas padrões
Roteamento dinâmico
O roteamento estático e padrão são manuais e geralmente são configurados via Rotas Estáticas, as quais são entradas manuais que “ensinam” ao roteador como encontrar uma rede remota.
Já os protocolos de roteamento IP dinâmicos não precisam da influência do administrador de Redes para descoberta dos melhores caminhos ou rotas até os destinos remotos.
Vamos ver a seguir os protocolos de roteamento IP dinâmicos com mais detalhes, afinal é o objetivo do artigo.
Funcionamento Geral dos Protocolos de Roteamento IP Dinâmicos
Quando temos uma topologia mais complexa o uso de protocolos de roteamento dinâmico é mais aconselhável, mas porque?
Imagine a inserção ou alteração dos elementos de rede manualmente, suponha que existam 100 rotadores na Rede e você adiciona ou altera alguma coisa? Loucura certo?
Com os protocolos de roteamento IP dinâmicos essa inserção ou remoção de rotas ou até mesmo dispositivos na rede fica bem mais simples e repassadas automaticamente para os demais dispositivos pelo elemento que sofreu a alteração, portanto, o que você muda em um é repassado dinamicamente para todos os outros.
O funcionamento macro dos protocolos de roteamento é bem semelhante, pois eles são processos habilitados nos roteadores que coletam informações das suas redes diretamente conectadas e repassam essas informações aos outros roteadores.
Com isso, um banco de dados é criado, analisado e através de um parâmetro de decisão chamado “métrica” a melhor rota é inserida na tabela de roteamento.
Além disso, os protocolos de roteamento devem atuar sobre alterações na rede por motivos de problemas, tais como a queda de um link de uma operadora ou um dispositivo que saiu do ar por falta de energia elétrica.
Nesses casos, a indisponibilidade daquelas redes deve ser refletida para todos os dispositivos.
Tipos de Protocolos de Roteamento IP Dinâmicos
Basicamente os protocolos de roteamento IP dinâmicos podem ser classificados pela área de abrangência e forma de funcionamento.
Por abrangência eles podem ser:
IGP: Interior Gateway Protocol ou
EGP: Exterior Gateway Protocol
O protocolos de roteamento IGP são utilizados dentro da Rede do provedor de serviço ou Rede corporativa.
São exemplos de IGP: RIP, OSPF, IS-IS, IGRP e EIGRP.
Já o EGP é utilizado na Internet, ou seja, entre Sistemas Autônomos. Atualmente o protocolo BGP é utilizado como EGP na Internet.
Além disso, esses mesmos protocolos tem um “jeito” de funcionar que depende do algoritmo que utiliza para descoberta de rotas e troca de informações de roteamento.
Temos os seguintes tipos de funcionamento:
Protocolos Vetor de Distância ou Distance Vector (exemplos: RIP e IGRP)
Protocolos Link State ou de estado de enlace (exemplos: OSPF e IS-IS)
Protocolos Híbridos ou vetor de distância avançado (exemplo: EIGRP)
Protocolos Path Vector (exemplo: BGP)
O funcionamento dos tipos 1, 3 e 4 são semelhantes, pois eles não conhecem a topologia da rede e sim qual o melhor próximo salto (seus vizinhos).
Já o estado de enlace (2) monta um banco de dados topológico, conhecendo a rede ou área como um todo.
Protocolos de Roteamento IP, Internet e Redes Corporativas
Atualmente na Internet o protocolo de roteamento utilizado entre os sistemas autônomos é o BGP.
Já nas Redes Corporativas utilizamos o RIP, OSPF ou IS-IS que são protocolos abertos, ou seja, funcionam entre fabricantes diferentes, e existe também um protocolo proprietário do fabricante Cisco que é muito famoso chamado EIGRP.
Um ou mais processos de roteamento podem ser ativados em um roteador, sendo que eles irão trocar informações e escolher internamente suas melhores rotas para cada destino baseado em uma “métrica” padrão que depende de cada protocolo.
Por exemplo, no RIP a melhor rota é a que tem menos saltos até o destino, já para o OSPF a melhor rota é a que tem menor custo (conta baseada no somatório da velocidade de cada link até o destino) sendo que a rota que tem a menor métrica (menor valor calculado) é considerada vencedora.
Caso tenhamos apenas um protocolo de roteamento habilitado essa rota, a que tem a menor métrica, é instalada na tabela de roteamento.
Quando temos mais de um protocolo de roteamento, ou seja, várias fontes de entrada para uma mesma rota vinda de diferentes protocolos, a distância administrativa ou custo é utilizado como critério de desempate.
Por exemplo, vamos supor que o RIP tem distância administrativa 120 e o OSPF 110 e ambos aprendem uma rota para a rede 192.168.0.0, qual delas o roteador instala na tabela de roteamento?
Será a aprendida via OSPF porque ela tem menor distância administrativa.
Na tabela de roteamento podemos ter várias rotas parecidas
com prefixos diferentes, por exemplo, uma rota para a rede 192.168.0.0 com o
prefixo /16 apontando para a interface 1 e outra rota para a rede 192.168.0.0
com o prefixo /24 apontando para a interface 2. Se calcularmos os IPs que cada
prefixo possui teremos que:
Dentro do /16 temos os IPs de 192.168.0.0 até
192.168.255.255
Dentro do /24 temos os IPs de 192.168.0.0 até
192.168.0.255
Note que a faixa de 0.0 até 0.255 está dentro das duas
rotas, mas qual o roteador irá escolher quando um IP de destino for, por
exemplo, 192.168.0.1?
Essa decisão sempre é tomada pelo prefixo mais longo, em
inglês “longest prefix match”, ou seja, quanto maior o prefixo maior é a
probabilidade daquela faixa de IP ser encontrada naquela interface saída, por
ele ser mais específico.
Portanto, no exemplo acima os pacotes serão enviados para a Interface 2!
Em outras palavras para clarear as coisas, quando falamos em prefixo mais longo estamos falando de máscara de subrede, ou seja, a interface 2 tem uma máscara de subrede /24 que é mais longa que a /16 da interface 1.
Isso quer dizer que a rede /24 será mais específica do que a /16, como temos menos hosts nessa subrede a probabilidade de se encontrar o host nessa rede será maior.
O que Melhora na Rede com um Protocolo de Roteamento?
Os ganhos são proporcionais a complexidade da sua rede.
Por exemplo, imagine que qualquer alteração de rede configurada com rota estática precisaria ser analisada e alterada roteador a roteador, um por um.
Como já citado anteriormente, imagine uma rede com mais de cem roteadores?
Além disso, os protocolos de roteamento dinâmico tem a capacidade de ajustar automaticamente quando problemas na rede ocorrem, claro que precisa ser planejada a redundância antes, mas você não precisaria reconfigurar nada para que uma nova rota seja descoberta e instalada nas tabelas de roteamento em TODA A REDE.
Outra vantagem é que os protocolos suportam o balanceamento de cargas sem precisar de dispositivos adicionais, existem algumas considerações e limitações, mas muita economia pode ser feita com o uso dos protocolos de roteamento na mão de um administrador de redes experiente.
Resumindo, NÃO TEM COMO FUGIR… quanto maior a rede maior a necessidade de protocolos de roteamento para garantir o funcionamento dela!
Como Aprofundar Meus Conhecimentos sobre Protocolos de Roteamento com a DlteC do Brasil?
Nesses cursos Online toda a teoria dos principais protocolos de roteamento serás abordada.
Também você poderá praticar em equipamentos ou simuladores de roteadores e switches nas trilhas de cursos da Cisco, indo além da teoria e vendo como as coisas funcionam na prática.
Com isso finalizamos mais um artigo!
Agradeço sua paciência e dedicação por ter chegado até aqui, pois saiba que muita gente lê o primeiro parágrafo apenas…
… portanto se você me acompanhou até aqui está de parabéns!
Se você achou o artigo útil e curte nosso trabalho vá além e compartilhe em seus grupos e com seus colegas!
Porque eu deveria estar pensando em um bom plano de endereçamento IPv6? Simples…
Você sabia que a taxa de adesão ao IPv6 está em quase 32% no Brasil (na data em que publicamos o artigo) e cresce exponencialmente?
E também que poucos profissionais dominam esse protocolo pra valer?
E que os órgãos Internacionais que administram a alocação de endereçamento de rede na Internet estão fazendo um trabalho de convencimento para ter uma rede cada vez mais IPv6?
Apesar que ainda por um bom tempo teremos que conviver com redes IPv4, quem sair antes vai ter muita vantagem competitiva no mercado de Infraestrutura de Redes.
O que é um Bom Plano de Endereçamento IPv6?
Segundo o NIC.br e demais órgãos internacionais que administram a alocação dos endereços IPv6, um bom plano de endereçamento IPv6 deve garantir:
Unicidade
Documentação
Conservação
Agregação
A unicidade quer dizer que cada endereço deve ser único no mundo, assim como você deve garantir que no seu projeto e implantação não exista duplicação de endereços ou redes.
A documentação quer dizer que você deve ter informações sobre os endereços gerenciados.
Mesmo em uma rede corporativa você deve documentar o projeto e implantação dos endereços, redes e sub-redes utilizadas por área, setor, localização geográfica ou tipo de serviço.
Além disso, é preciso saber os endereços que estão sendo utilizados ou não, por exemplo, o NIC.br tem a documentação dos endereços entregues e que blocos estão disponíveis, senão seria impossível administrar a Internet.
A conservação é a utilização responsável, inteligente e sem desperdício.
Apesar do IPv6 trazer uma quantidade descomunal de endereços, não devemos utilizá-los de forma irresponsável.
A agregação está relacionada ao roteamento, pois na Internet o protocolo de roteamento BGP não sabe cada endereço final e sim onde estão os diversos blocos de endereços IP.
Como a quantidade de redes na Internet com o IPv6 tende a disparar, se esses anúncios não forem realizados de forma correta as tabelas de roteamento dos roteadores de Internet poderia crescer de uma forma descontrolada e até perigosa.
Pois imagine a quantidade de memória para armazenar as entradas de tabela de roteamento numa rede IPv6 mal feita?
Agora vamos falar um pouco mais sobre como iniciar um plano de endereçamento IPv6.
Como Iniciar o Plano de Endereçamento IPv6
A primeira coisa que deve ser feita é levantar as topologias e o plano de endereçamento realizado para o IPv4.
Espera-se que toda empresa tenha a documentação da rede, do endereçamento, sub-redes por setor, localidade ou função, etc.
Se sua empresa não possui tal documentação é uma boa hora para fazê-la, pois você já colocará tanto a rede IPv4 em dia como terá um ótimo ponto de partida para o projeto da rede IPv6.
Lembre-se que em uma rede IPv4 temos endereços IP fixos ou dinâmicos, alocados via DHCP.
Normalmente os IPs fixos são alocados nos dispositivos de Redes, tais como roteadores, switches e access points, assim como em servidores (sejam eles físicos ou máquinas virtuais), impressoras e demais dispositivos que necessitam ter sempre o mesmo endereço IP.
Já os clientes IPv4 recebem seus endereços de camada-3 via o serviço de DHCP, o qual pode ser centralizado ou não. Lembre que para um DHCP centralizado será necessário o uso do DHCP Relay nos roteadores e/ou switches L3 que conectam os clientes.
Portanto essa é uma fase de investigação, descoberta da rede e até atualização, pois acredite em mim, muita coisa muda e não é documentada na prática.
Com isso tudo em mãos você saberá onde, quem e que tipo de endereço IPv6 será necessário.
Apenas cuidado porque o IPv6 pode ter endereçamento fixo, via DHCPv6 e SLAAC, sendo que o último vem ativado como padrão em quase todos os clientes IPv6 e isso pode causar um transtorno na sua rede se não for escolhido o método de alocação de IPs para os clientes antes do início da implantação.
Outro ponto importante de diferença é que no IPv6 não existe o endereço privativo que pode ser traduzido via NAT para acesso à Internet.
Ou seja, vamos ter endereços válidos em toda a rede, portanto planeje também a segurança para que não tenha problemas com invasões, vírus e ataques aos clientes IPv6.
Distribuição de Endereços IPv6
Os endereços IPv6 são administrados pela IANA, a qual delega a administração para o LACNIC, que por sua vez repassa esse controle dos endereços IPv6 no Brasil para o NIC.BR.
O NIC.BR por sua vez administra a alocação dos endereços IPv6 no Brasil para os Provedores de Internet e Sistemas Autônomos.
Na prática, cada RIR como o LACNIC recebe da IANA um bloco com o comprimento /12 de endereços IPv6.
O LACNIC tem atualmente o bloco de endereço IPv6 2800::/12.
O NIC.br usa o bloco 2804::/16, o qual faz parte desse bloco 2800::/12 do LACNIC. Além disso, ele trabalha também com blocos menores (provenientes de alocações antigas), os quais são os blocos 2001:1280::/25 e 2801:0080::/26.
Já a alocação mínima para ISPs é um bloco /32, mas alocações maiores podem ser feitas mediante solicitação e justificativa de utilização.
A recomendação para alocação de usuários domésticos são blocos de endereços /64 a /56.
Já para clientes corporativos são blocos /48.
Os endpoints (computadores, servidores e dispositivos móveis) devem utilizar preferencialmente prefixos /64, porém você pode usar faixas menores como um /60 para criar sub-redes para servidores em seu Data Center interno, por exemplo.
Para servidores externos a recomendação é utilizar prefixos /64 para designar os servidores.
Está previsto também o uso de prefixos /127 para endereçar links ponto a ponto e /128 para loopbacks dos dispositivos de Rede.
Revisando o Endereço IPv6 e Sub-redes
Note abaixo a figura com um endereço IP versão 6 e seus principais blocos de alocação de bits.
Como já citamos nos textos anteriores, vamos ressaltar os seguintes pontos:
Um endereço IPv6 tem 128 bits e que prefixos /128 podem ser utilizados para endereçar as Loopbacks dos dispositivos de Rede.
Esses 128 bits são divididos em 32 algarismos em Hexadecimal (0-9 e A-F).
O tamanho mais normal de uma sub-rede e o que vamos utilizar para os clientes é um /64.
/48 é normalmente utilizada para clientes corporativos, mas também podemos utilizar a opção de /56 tanto para empresas menores como clientes residenciais que necessitem de mais sub-redes.
/48 deve ser o menor prefixo a ser anunciado via BPG na Internet.
/32 é normalmente o tamanho do prefixo que um provedor de serviços receberá do Nic.br
Para termos uma ideia de tamanho, uma /32 tem 16 milhões de /56 dentro dela ou então 65.536 redes /48.
Com uma rede /48 podemos criar 65.536 redes /64, o que é o tamanho de uma rede IPv4 classe B.
E com uma rede /56 pode criar 256 redes /64.
Recomenda-se fazer a divisão de sub-redes no IPv6 utilizando 4 bits, pois assim temos a variação completa do Hexadecimal e facilita muito o entendimento das sub-redes.
Se você tem dúvidas sobre o formato do IPv6 e os tipos de endereços recomendo que você leia esse artigo e depois volte para continuar a leitura do artigo atual:
Endereçando a Infraestrutura de Redes IPv6 em ISPs
O que devemos considerar para fazer o plano de endereçamento IPv6 em uma rede de um provedor de serviços de Internet ou ISP? Veja abaixo alguns exemplos.
Endereços de Loopback dos dispositivos de rede
Links Ponto-a-ponto
Rede MPLS
Rede Metroethernet e Fibra
Redes para servidores Internos (Gerenciamento de Rede, servidores do NOC, etc)
Servidores de redes externas (E-mail, DNS, etc)
Endereços das LANs dos funcionários do ISP
Redes para clientes corporativos e residenciais
Vamos começar pela Infraestrutura interna do provedor de serviços de internet ou ISP (Internet Service Provider).
Por exemplo, para as loopbacks pode ser reservada uma rede /48 para endereçar as interfaces prefixos /128. Para redes menores pode ser utilizado prefixo /60 ou /64 para esse fim.
Em redes ponto a ponto podemos dedicar uma rede /64 e dividí-la em várias sub-redes /127, como recomendam as RFCs 6164 e 6457.
Para servidores internos podemos utilizar uma rede /64 ou então utilizar sub-redes /60 e dividir essa rede em várias sub-redes /64.
Servidores externos podemos alocar uma /64, pois ela trará a possibilidade de 18.446.744.073.709.551.616 servidores ou serviços de rede alocados.
Até o momento falamos em alocar uma /64, por exemplo, par os servidores internos, porém se o provedor é grande e tem vários Data Centers espalhados podem ser necessárias mais redes e sub-redes, pois a topologia física e a distribuição geográfica dos dispositivos pode influenciar nessa decisão.
Alocação para Clientes Corporativos, Residenciais e Data Centers (ISP)
Quando falamos de clientes corporativos de um ISP o mais recomendado é a utilização de redes /48 para clientes maiores (possibilidade de mais de 65 mil sub-redes) ou alocar blocos menores de IPV6.
Por exemplo, utilizar blocos /52 ou /56 ou até mesmo blocos /60, porém no Brasil a recomendação é utilizar /56.
Os links WAN para clientes corporativos ou empresariais segue o mesmo princípio para a rede Interna do ISP, podemos alocar uma rede /64 e quebrá-la em diversas sub-redes IPv6 /127.
Já para os clientes residenciais, normalmente eles serão conectados a uma rede Banda Larga tal como ADSL, Fibra ou até mesmo sem fio.
Para isso pode ser alocada uma rede /48 e alocar para esses clientes residenciais um prefixo /64 utilizando DHCPv6 e PPPoE.
Para o Data Center externo, aquele que é utilizado para os clientes finais do ISP, a lógica é a mesma de sempre.
Podemos alocar blocos /40 ou /48 e dividir esses blocos em várias redes /64 para criação das VLANs dos clientes ou serviços oferecidos pelo Data Center.
Sumarização e Engenharia de Tráfego para ISPs com IPv6
Assim como é realizado para o IPv4, no IPv6 temos que pensar em sumarização de redes para facilitar a engenharia de tráfego e balanceamento de cargas.
Por exemplo, o provedor pode dividir seu /32 em dois blocos /33, o qual pode ser dividido em 4 blocos /34 e fazer o balanceamento de cargas entre os links para evitar sobrecarga em apenas um circuito de comunicação.
Plano de Endereçamento IPv6 para Empresas e Clientes Residenciais
Vamos começar pelo mais fácil que são os clientes residenciais.
Nesse momento da tecnologia e implantação do IPv6, se você é cliente residencial banda larga com IPv6 não tem muito o que se preocupar, pois toda configuração é realizada automaticamente pelo provedor a partir do seu CPE (dispositivo final instalado nas residências).
Se você for um usuário do tipo corporativo que em um small office ou home office e precisar de mais de uma sub-rede IPv6 terá que entrar em contato com o provedor para uma solução diferente do tradicional, porém não conheço pessoalmente esse tipo de necessidade até o momento com implantações IPv6.
Já em ambientes corporativos ou empresariais o esquema do planejamento deve se basear na infraestrutura atual da empresa e seguir os padrões definidos para o IPv4 com sub-redes, mas agora com IPv6.
Você deve a partir da sua topologia de rede verificar:
Saída de Internet
DMZ e serviços externos como E-Mail, DNS e servidores HTTP
Servidores e serviços internos
LANs e VLANs corporativas
Links WAN
Loopbacks dos dispositivos de Rede
Definir os escopos de entrega de endereço dinâmico
Faixa de dispositivos que não são da infraestrutura de Rede com endereçamento fixo
A grande diferença é que para o IPv6 não existe mais a figura do NAT, onde “escondemos” os endereços internos utilizando a RFC1918 ou endereços privativos.
No IPv6 você vai receber um /48 ou /56 e vai utilizar endereços roteáveis na Internet em TODA A SUA REDE.
Será muito importante definir as políticas de filtragem e acesso da Internet em direção à sua rede local, pois o IPv6 funciona dessa maneira agora.
Mas, por exemplo, se sua empresa receber um endereço IPv6 com prefixo /48 você terá a possibilidade de criar mais de 65mil sub-redes, sendo que cada sub-rede suportará 18.446.744.073.709.551.616 endereços por sub-rede.
Agora não precisamos mais aquele cuidado absurdo com o desperdício que existia no IPv4, porém isso não quer dizer que você pode usar de qualquer maneira, pois o não desperdício e uso racional dos endereços ainda é objetivo no IPv6.
Exemplo de Plano de Endereçamento IPv6 para Ambientes Corporativos
Vamos supor que você é o administrador de redes e recebeu um bloco /48 para dividir os endereços da empresa que trabalha conforme abaixo.
2001:db8:1234::/48
Portanto a porção do endereço 2001:db8:1234 é fixa, pois são os 48 bits do prefixo do bloco, pois cada algarismo em hexadecimal tem 4 bits.
Seguindo essa analogia, se considerarmos que os hosts terão 64 bits de interface ID, temos um total de 16 bits para criação das sub-redes (64 – 48).
Isso dará um total de 65.563 sub-redes /64, conforme figura abaixo.
Se utilizarmos 4 bits (que é o recomendado) para dividir nossas sub-redes, podemos utilizar da esquerda para a direita, o primeiro algarismo para definir 16 localizações, o segundo para definir 16 funções e os dois últimos para definir as sub-redes.
Por exemplo, o site de Curitiba seria o primeiro 2001:db8:1234::/49.
Nele podemos ter 16 tipos de serviços ou até mesmo setores, mas vamos por serviços:
Loopbacks: 2001:db8:1234::/50
VLANs dos setores: 2001:db8:1234:100::/50
Gerenciamento: 2001:db8:200::/50
WANs: 2001:db8:1234:300::/50
VLANs dos Servidores corportivos: 2001:db8:1234:400:/50
Por exemplo, se vamos definir uma das VLANs corporativas, a do setor comercial, ela poderia ser 2001:db8:1234:100::/64, a segunda para o setor de pós vendas poderia ser 2001:db8:1234:101::/64 e assim por diante.
Como posso aprender mais sobre IPv6 no Portal da DlteC do Brasil?
O IPv6, suas características, endereçamento, funcionamento e tudo mais que você precisa podem ser estudados em nosso Portal através das carreiras de certificação Cisco ou através do curso de IPv6.
Outra opção é o curso de sub-redes IPv6, o qual trata exclusivamente de como dividir Redes IPv6 em Sub-redes utilizando qualquer quantidade de bits ou alocações.
Então com isso finalizamos nosso artigo!
Muito obrigado pela leitura e pela confiança em nosso trabalho!
Não esqueça de fazer seu comentário e compartilhar nosso artigo em suas redes sociais!
O OSPF é um dos protocolos de roteamento internos mais utilizados em empresas e provedores de serviços como IGP, sendo que ele possui duas versões: OSPFv2 ou somente OSPF e o OSPFv3.
Se você não conhece o OSPF leia primeiro os artigos abaixo depois não esqueça de voltar para cá, combinado?
A diferença entre o protocolo OSPF ou OSPFv2 e o OSPFv3 é o tipo de protocolo de camada-3 que cada um suporta.
O OSPF ou OSPFv2 foi feito para dar suporte ao IPv4 ou protocolo IP versão 4, já o OSPFv3 dá suporte ao IPv6 ou protocolo IP versão 6.
Em termos básicos de funcionamento, se você já trabalha com o OSPF para IPv4 não vai ter dificuldades de entender e até mesmo configurar o OSPFv3 em roteadores e switches layer-3 Cisco.
O protocolo OSPFv3 continua sendo do tipo Link State, utilizando o algoritmo de Dijkstra para descoberta do melhor caminho, a métrica é o custo da interface (baseando-se na largura de banda), sua distância administrativa é 110, os tipos de interface continuam os mesmos, ainda tem eleição de DR (Designated Router) e BDR (Backup Designated Router) para interfaces Multiacesso, ou seja, maioria das características gerais continuam as mesmas.
Outra semelhança importante entre os protocolos OSPF para IPv4 e IPv6 é que ambos suportam dois tipos básicos de arquitetura:
Single Area: todos os roteadores situados na área zero ou de backbone
Multi Area: utilizando diversas áreas para melhorar a segmentação da rede e facilitar a agregação de prefixos.
As principais mudanças são:
O processamento do Protocolo é por link e não mais por sub-rede
Adição de escopo de Flooding
Suporte a múltiplos links por instância
Utiliza o endereço IPv6 de link-local para trocar informações
Mudança nos métodos de autenticação
Formato do pacote e tipos de LSA
Suporte a LSAs do tipo desconhecido (unknown LSA)
Configurações Básicas do OSPFv3 no Cisco IOS
Em termos de configuração, maioria dos roteadores e switches L3 Cisco não iniciam com o protocolo IPv6 ativado por padrão, portanto para trabalhar com o OSPFv3 você precisará ativá-lo com o comando abaixo.
Para entrar em modo de configuração do protocolo de roteamento no OSPFv2 você digita o comando (configuração global):
DlteC(config)#router ospf 1
Sendo que o número “1” é o número de identificação do processo ou process ID (PID).
No caso do OSPFv3 você também entra no processo de roteamento via configuração global, porém com o comando:
DlteC(config)#ipv6 router ospf ? <1-65535> Process ID DlteC(config)#ipv6 router ospf 1
Onde o “1” ainda é o número do processo ativado para essa instância do OSPFv3.
Outro parâmetro fundamental para o OSPFv3 é o router-id ou identificação do roteador para o processo de roteamento.
Por mais estranho que pareça, essa identificação é um número no formato do IPv4, veja exemplo abaixo.
ipv6 router ospf 1 router-id 7.7.7.7
Sobre as interfaces e redes que entrarão no processo de roteamento, o famoso “redes anunciadas” pelo protocolo de roteamento, para o OSPFv2 você pode fazer a configuração duas maneiras:
Utilizando o comando Network dentro do modo de configuração do protocolo de roteamento ou
Definindo através da Interface
Já no OSPFv3 existe apenas a opção de configuração através do mode de Interface, não existe mais o comando Network, veja exemplo abaixo.
interface giga 0/0 ip address 10.0.10.7 255.255.255.0 ipv6 enable ipv6 address 2001:BABA::/64 eui-64 ipv6 ospf 1 area 0
Note que ambas as versões de OSPF trabalham com o conceito de áreas, portando no comando Network para OSPFv2, assim como no anúncio dentro da interface temos que identificar o número do processo do OSPF (1 no exemplo acima) e a área que essa interface estará vinculada (zero no exemplo acima).
Exemplo Prático de Configuração do OSPFv3
Abaixo segue a topologia e as configurações para ativação do roteamento via OSPFv3 para o protocolo IPv6.
Para realizar e testar as configurações foi utilizado um laboratório simulado e roteadores modelo Cisco 1841 com interfaces WIC-1T no módulo-0 de cada um dos dispositivos.
Roteador DlteC1
ipv6 unicast-routing ! ipv6 router ospf 1 router-id 1.1.1.1 ! interface FastEthernet0/0 no ip address ipv6 address 2003::1/124 ipv6 enable ipv6 ospf 1 area 0 ! interface Serial0/0/0 no ip address ipv6 address 2002:ABAB::1/64 ipv6 enable ipv6 ospf 1 area 2
Roteador DlteC2
ipv6 unicast-routing ! interface serial 0/0/0 no ip address ipv6 enable ipv6 address 2002:ABAB::2/64 ipv6 ospf 1 area 2 ! ipv6 router ospf 1 router-id 2.2.2.2
Roteador DlteC3
ipv6 unicast-routing ! interface FastEthernet0/0 no ip address ipv6 address 2003::2/124 ipv6 enable ipv6 ospf 1 area 0 ! interface Serial0/0/0 no ip address ipv6 address 2003::1:1/124 ipv6 ospf 1 area 3 ! ipv6 router ospf 1 router-id 3.3.3.3
Roteador DlteC4
ipv6 unicast-routing ! interface Serial0/0/0 no ip address ipv6 address 2003::1:2/124 ipv6 enable ipv6 ospf 1 area 3 ! ipv6 router ospf 1 router-id 4.4.4.4
Apesar desse artigo não tratar de comandos para verificar as configurações, você pode utilizar o ping/trace/telnet para testar o alcance da rede, assim como os seguintes comandos show para esse fim (exemplos tirados do roteador DlteC1):
show ipv6 route
DlteC1#show ipv6 route IPv6 Routing Table - 6 entries Codes: C - Connected, L - Local, S - Static, R - RIP, B - BGP U - Per-user Static route, M - MIPv6 I1 - ISIS L1, I2 - ISIS L2, IA - ISIS interarea, IS - ISIS summary O - OSPF intra, OI - OSPF inter, OE1 - OSPF ext 1, OE2 - OSPF ext 2 ON1 - OSPF NSSA ext 1, ON2 - OSPF NSSA ext 2 D - EIGRP, EX - EIGRP external C 2002:ABAB::/64 [0/0] via ::, Serial0/0/0 L 2002:ABAB::1/128 [0/0] via ::, Serial0/0/0 C 2003::/124 [0/0] via ::, FastEthernet0/0 L 2003::1/128 [0/0] via ::, FastEthernet0/0 OI 2003::1:0/124 [110/65] via FE80::2D0:D3FF:FEA3:1901, FastEthernet0/0 L FF00::/8 [0/0] via ::, Null0 DlteC1#
show ipv6 ospf
DlteC1#show ipv6 ospf Routing Process "ospfv3 1" with ID 1.1.1.1 SPF schedule delay 5 secs, Hold time between two SPFs 10 secs Minimum LSA interval 5 secs. Minimum LSA arrival 1 secs LSA group pacing timer 240 secs Interface flood pacing timer 33 msecs Retransmission pacing timer 66 msecs Number of external LSA 0. Checksum Sum 0x000000 Number of areas in this router is 2. 2 normal 0 stub 0 nssa Reference bandwidth unit is 100 mbps Area BACKBONE(0) Number of interfaces in this area is 1 SPF algorithm executed 8 times Number of LSA 7. Checksum Sum 0x0419be Number of DCbitless LSA 0 Number of indication LSA 0 Number of DoNotAge LSA 0 Flood list length 0 Area 2 Number of interfaces in this area is 1 SPF algorithm executed 5 times Number of LSA 6. Checksum Sum 0x036bde Number of DCbitless LSA 0 Number of indication LSA 0 Number of DoNotAge LSA 0 Flood list length 0 DlteC1#
show ipv6 ospf interface
DlteC1#show ipv6 ospf interface FastEthernet0/0 is up, line protocol is up Link Local Address FE80::202:17FF:FE74:2701, Interface ID 1 Area 0, Process ID 1, Instance ID 0, Router ID 1.1.1.1 Network Type BROADCAST, Cost: 1 Transmit Delay is 1 sec, State BDR, Priority 1 Designated Router (ID) 3.3.3.3, local address FE80::202:17FF:FE74:2701 Backup Designated Router (ID) 1.1.1.1, local address FE80::202:17FF:FE74:2701 Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5 Hello due in 00:00:03 Index 1/1, flood queue length 0 Next 0x0(0)/0x0(0) Last flood scan length is 1, maximum is 1 Last flood scan time is 0 msec, maximum is 0 msec Neighbor Count is 1, Adjacent neighbor count is 0 Suppress hello for 0 neighbor(s) Serial0/0/0 is up, line protocol is up Link Local Address FE80::202:17FF:FE74:2701, Interface ID 3 Area 2, Process ID 1, Instance ID 0, Router ID 1.1.1.1 Network Type POINT-TO-POINT, Cost: 64 Transmit Delay is 1 sec, State POINT-TO-POINT, Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5 Hello due in 00:00:03 Index 2/2, flood queue length 0 Next 0x0(0)/0x0(0) Last flood scan length is 1, maximum is 1 Last flood scan time is 0 msec, maximum is 0 msec Neighbor Count is 1 , Adjacent neighbor count is 1 Adjacent with neighbor 2.2.2.2 Suppress hello for 0 neighbor(s) DlteC1#
Como Aprender mais sobre OSPFv2 e OSPFv3 na DlteC?
Em nosso Portal de cursos temos duas opções de estudo sobre redes IPv4 e IPv6:
Trilha de cursos Express sobre roteamento IP e OSPF
Trilha de certificações Cisco Routing and Switching ou Enterprise (após 24 de fevereiro de 2020)
Ambas as trilhas são excelentes para o aprendizado do funcionamento e configuração do OSPF tanto para IPv4 como para IPv6.
Então vamos finalizar o artigo, parabéns se você leu até aqui e me acompanhou até o final…
… saiba que você está de parabéns por isso!
Muito obrigado e até um próximo artigo.
Ah, já ia esquecendo… se você gostou do artigo compartilhe com seus amigos, grupos e redes sociais, nos ajude a divulgar conhecimento com a galera da área de Infra de Redes.
E se você tem alguma dúvida, comentário ou até mesmo um elogio utilize o campo de comentários que tem descendo a página!
Vou dar uma ótima notícia nesse artigo que é a oportunidade de ter a Segunda Chance Grátis para o CCNA 200-125 e ICND-2 200-105 em caso de reprovação… mas leia até o final porque tem algumas “pegadinhas”…
… senta que essa oportunidade que a Cisco vai dar na reta final da virada para o CCNAX e ICND-2 é inacrditável.
Primeiro deixa eu dizer aqui que NÃO QUERO QUE NENHUM ALUNO REPROVE!
Nosso índice de aprovação está fantástico, só em janeiro de 2020 (quando escrevi esse artigo) tivemos 14 aprovações, sendo que três alunos GABARITARAM suas provas, tiraram 1000 pontos!
Entraram em nosso grupo mais um CCENT, seis CCNAs R&S, dois CCNAs Security e três CCNPs R&S, os demais estão a caminho de completar suas trilhas.
Mas vamos lá para a oportunidade de ouro!
A Cisco lançou um plano de backup (chamada de Cisco Assurance offer) para quem está se preparando para as provas do ICND2 200-105 e CCNAx 200-125 antes da virada de 24 de fevereiro desse ano e…
… vai LIBERAR A SEGUNDA TENTATIVA GRATUITA em caso de reprovação.
Isso mesmo, quem reprovar vai poder fazer seu ICND-2 200-105 ou CCNAX 200-125 “na faixa”!
O que eu preciso fazer para ter a Segunda Chance Grátis para o CCNA 200-125 e ICND-2 200-105?
“Comprar a prova utilizando o código de cupom LSTPUSH20” e caso reprove faça a compra da segunda tentativa com o mesmo código (LSTPUSH20) que ela terá um desconto de 100%. SIMPLES ASSIM.
E se eu já reprovei em uma dessas duas provas e não comprei com esse código de cupom?
“Existe precedente que ao colocar o código na compra da segunda tentativa o valor ficou zerado, ou seja, ao inserir LSTPUSH20 no campo do código de cupom deu 100% de desconto”.
Então se você reprovou no 200-125 ou 200-105 vai lá e tenta comprar a prova com esse cupom, se zerar o valor FAÇA SUA SEGUNDA TENTATIVA NA FAIXA! Não perca essa chance.
CUIDADOS E PEGADINHAS com essa Oportunidade!
Para fazer a segunda vez o mesmo exame que você venha a reprovar (chamado de retake) é preciso esperar um prazo de 5 (cinco) dias úteis para remarcar a prova.
Então não adianta agendar para o dia 20 de fevereiro achando que se reprovar vai ter segunda chance PORQUE NÃO VAI TER TEMPO HÁBIL.
A recomendação é agendar pelo menos com 10 a 15 dias antes da data limite que é 23/02, portanto até a semana do dia 10 de fevereiro.
Outro ponto é que os centros da Pearson Vue que aplicam a prova NÃO PRECISAM seguir esse cronograma, eles mesmos definem seus cronogramas.
Por isso, se você está pensando em fazer a prova agende o quanto antes para não ficar de fora por falta de agenda na sua cidade ou região!
Espero que essa dica ajude a você tomar coragem e enfrentar o CCNAX ou o ICND2 (caso tenha o CCENT válido), pois com a segunda chance “na faixa” dá uma segurança a mais!
Muito obrigado pela atenção e até uma próxima dica!
Você sabe o que quer dizer CCNA e porque está nesse artigo escrito CCNA 200-301?
Se você sabe parabéns, mas se não sabe CCNA quer dizer Cisco Certified Network Associate, ou seja, a certificação nível associado (um iniciante) desse fabricante de dispositivos de Infra de Redes e mais uma infinidade de produtos e tecnologias.
Certificação é a palavra chave, pois é uma prova que vai medir se você tem conhecimentos teóricos e práticos de vários assuntos relacionados a diversas tecnologias e configurações desses dispositivos do fabricante Cisco.
E o que pode acontecer de pior quando você decide entrar em um processo de certificação e passar em uma prova como o CCNA 200-301? Reflete um pouco e vamos ver se pensamos parecido…
Nós acreditamos que não é uma coisa só e sim duas: 1) Reprovar e perder o dinheiro investido (em dólares!) 2) Passar utilizando subterfúgios obscuros (cola e decoreba) e não dar conta do recado quando entrar no mercado de trabalho (certificado de papel, ou seja, decorou tudo e não sabe trabalhar)
Nós tratamos dos dois problemas em nosso Portal, o curso tem foco para nossos alunos serem aprovados e também ir bem no mercado de trabalho.
Mas entrar em um processo de certificação deveria ser encarado um pouco mais a sério e o candidato deveria ir a fundo na proposta do fabricante, por isso mesmo resolvemos escrever esse artigo e dar mais detalhes sobre o que pode ser cobrado nesse exame de certificação da Cisco.
A Prova CCNA 200-301: Características e Quanto Custa
O exame CCNA 200-301 substitui diversos CCNAs que existem atualmente, sendo que essa prova inicia dia 24 de fevereiro de 2020.
O conteúdo do CCNA 200-301 se baseia no CCNA Routing abd Switching atual (CCNAX 200-125, CCENT/ICND-1 100-105 e ICND-2 200-105), pois terá 70% do seu conteúdo trazido desse exame que terá sua data limite de existência em 23 de fevereiro de 2020.
Além disso, existem mais 30% de conteúdo que serão trazidos do CCNA Security, CCNA Wireless, assim como novidades sobre programabilidade e automação de redes.
Além disso, não haverá mais a possibilidade de fazer o CCNA em duas provas como na versão 200-125 do CCNA R&S.
O exame de certificação CCNA 200-301 já está disponível para compra no site da PearsonVue (quem aplica as provas da Cisco) pelo valor de US$255 (duzentos e cinquenta e cinco dólares americanos).
O tempo de realização da prova está previsto para um máximo de 120 minutos, porém normalmente para pessoas que não são de países onde o inglês é a língua nativa normalmente existe um tempo extra de 30 minutos, porém não confirmado até o momento que escrevi esse artigo.
Ainda não foi divulgado o número de questões que podem ser cobradas durante o exame, porém acredito que fique próximo a 60 questões.
Tipos de Questões da Certificação CCNA 200-301
Nesse ponto não existe novidade, os tipos de questão para o CCNA 200-301 são os de sempre:
Múltipla escolha com uma ou diversas escolhas (Multiple-Choice Single Answer e Multiple-Choice Multiple Answer)
Drag and Drog (arrastar a resposta certa)
Preencher a lacuna (fill-in-the-blank)
Testlet (várias perguntas em uma única questão)
Simulação (configurações e verificações de roteadores e switches Cisco)
Simlet (perguntas que para serem respondidas precisam de análise de configurações ou comandos show)
O interessante é que esse de preencher ou fill-in-the-blank é bem raro de ser cobrado, mas está listado como um tipo possível de questão.
Conteúdo da Prova ou Blueprint do CCNA 200-301
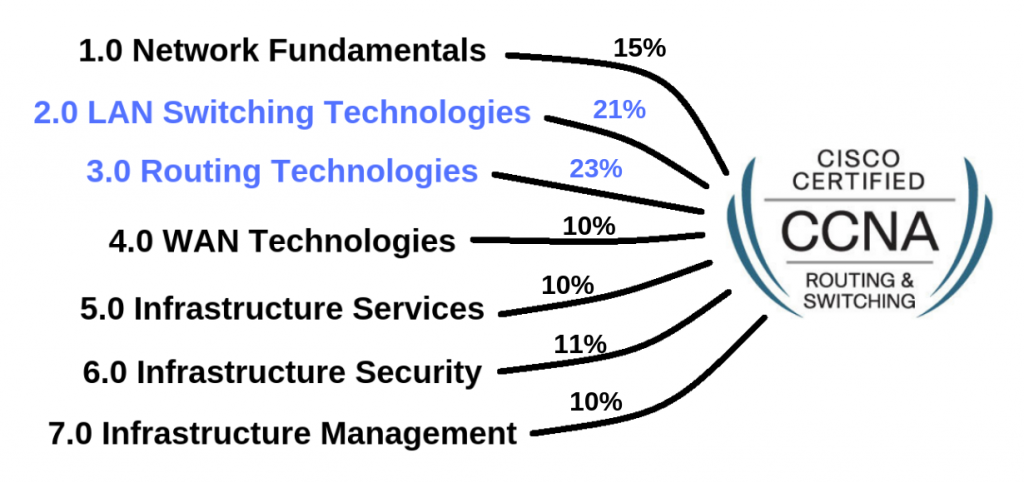
Os tópicos das provas de certificação da Cisco CCNA 200-301 são divulgados através do Blueprint do exame, o qual é uma listagem dos tópicos e pesos de cada um deles na prova.
Veja na imagem a seguir os tópicos, seus pesos na prova e as tecnologias, protocolos e recursos que cada um deles abrange.
Note que cairão mais questões sobre os itens 1, 2 e 3 na certificação Cisco CCNA 200-301, sendo que o último representa 1/4 da prova toda!
Portanto, fundamentos de redes, switching/VLANs e roteamento continuam sendo a maioria das questões nessa prova! Veja a figura abaixo que mostra a mesma coisa em um formato diferente.
Agora vamos ver o que cai em cada item do blueprint do CCNA 200-301.
Network Fundamentals
No tópico 1 temos os fundamentos de redes, ou seja, a base que todo certificado nível associado deve conhecer segundo a Cisco.
Basicamente o tópico 1 vai cobrar conhecimentos sobre routers, switches L2 e L3, next-generation firewalls (NGFWs), IPS, wireless lan controllers (WLC), DNA center, wireless access points (WAPs), endpoints/servers, princípios de wireless, conceitos de switching, topologias, TCP vs UDP, configurar e verificar endereços IPv4 e IPv6.
Veja os tópicos abaixo (em negrito são novos em relação ao exame CCNA R&S 200-125).
1.0 Network Fundamentals
1.1 Explain the role and function of network components 1.1.a Routers 1.1.b L2 and L3 switches 1.1.c Next-generation firewalls and IPS 1.1.d Access points 1.1.e Controllers (Cisco DNA Center and WLC) 1.1.f Endpoints 1.1.g Servers
1.2 Describe characteristics of network topology architectures 1.2.a 2 tier 1.2.b 3 tier 1.2.c Spine-leaf 1.2.d WAN 1.2.e Small office/home office (SOHO) 1.2.f On-premises and cloud
1.3 Compare physical interface and cabling types 1.3.a Single-mode fiber, multimode fiber, copper 1.3.b Connections (Ethernet shared media and point-to-point) 1.3.c Concepts of PoE
1.13 Describe switching concepts 1.13.a MAC learning and aging 1.13.b Frame switching 1.13.c Frame flooding 1.13.d MAC address table
Network Acces
O segundo item do blueprint do 200-301 trata de Switching e redes em fio.
Você deverá ser testado sobre Spanning Tree Protocol (STP), trunks, 802.1Q, Native VLAN, wireless LAN (WLAN), Configurar o Cisco Discovery Protocol (CDP), Link Layer Discovery Protocol (LLDP), EtherChannel (LACP), PoE, configurar Access Points e descrever conexões entre APs e Switches.
Os seguintes itens fazem parte desse tópico (em negrito são novidades em relação do CCNA 200-125):
2.3 Configure and verify Layer 2 discovery protocols (Cisco Discovery Protocol and LLDP)
2.4 Configure and verify (Layer 2/Layer 3) EtherChannel (LACP)
2.5 Describe the need for and basic operations of Rapid PVST+ Spanning Tree Protocol and identify basic operations
2.5.a Root port, root bridge (primary/secondary), and other port names
2.5.b Port states (forwarding/blocking)
2.5.c PortFast benefits
2.6 Compare Cisco Wireless Architectures and AP modes
2.7 Describe physical infrastructure connections of WLAN components (AP,WLC, access/trunk ports, and LAG)
2.8 Describe AP and WLC management access connections (Telnet, SSH, HTTP,HTTPS, console, and TACACS+/RADIUS)
2.9 Configure the components of a wireless LAN access for client connectivity using GUI only such as WLAN creation, security settings, QoS profiles, and advanced WLAN settings
IP Connectivity
O terceiro item cobre o roteamento e a conectividade IP na rede.
Você deverá saber sobre roteamento estático e dinâmico, OSPF (Open Shortest Path First) single area, rotas estáticas IPv4 e IPv6 (Default route, Network route, Host route e Floating static), assim como descrever os protocolos de redundância de primeiro salto ou FHRP.
Nesse item sai o RIPv2 e o EIGRP, ficando apenas o OSPF como protocolo de roteamento.
Os seguintes itens fazem parte desse tópico (sem novidades em relação ao CCNA 200-125):
3.0 IP Connectivity
3.1 Interpret the components of routing table 3.1.a Routing protocol code 3.1.b Prefix 3.1.c Network mask 3.1.d Next hop 3.1.e Administrative distance 3.1.f Metric 3.1.g Gateway of last resort
3.2 Determine how a router makes a forwarding decision by default
3.2.a Longest match
3.2.b Administrative distance
3.2.c Routing protocol metric
3.4 Configure and verify single area OSPFv2
3.4.a Neighbor adjacencies
3.4.b Point-to-point
3.4.c Broadcast (DR/BDR selection)
3.4.d Router ID
3.5 Describe the purpose of first hop redundancy protocol
IP Services
Nesse quarto item serão cobrados conceitos e configurações sobre os serviços IP, tais como Syslog, NAT, NTP, DHCP, DNS, SNMP, QoS e SSH.
Os seguintes itens fazem parte desse tópico (sem novidades em relação ao CCNA 200-125):
4.0 IP Services
4.1 Configure and verify inside source NAT using static and pools
4.2 Configure and verify NTP operating in a client and server mode
4.3 Explain the role of DHCP and DNS within the network
4.4 Explain the function of SNMP in network operations
4.5 Describe the use of syslog features including facilities and levels
4.6 Configure and verify DHCP client and relay
4.7 Explain the forwarding per-hop behavior (PHB) for QoS such as classification, marking, queuing, congestion, policing, shaping
4.8 Configure network devices for remote access using SSH
4.9 Describe the capabilities and function of TFTP/FTP in the network
Security Fundamentals
Nos fundamentos de segurança, o quinto item do blueprint do CCNA 200-301 teremos que enfrentar questões sobre conceitos de segurança, ameaças, vulnerabilidades, multi-factor authentication (MFA), Implementar site-to-site VPN, access control lists (ACLs), segurança na camada-2 (DHCP snooping, dynamic ARP inspection e port security) e segurança em rede sem fio (WPA, WPA2 e WPA3).
Os seguintes itens fazem parte desse tópico (em negrito são novidades em relação do CCNA 200-125):
5.2 Describe security program elements (user awareness, training, and physical access control)
5.3 Configure device access control using local passwords
5.4 Describe security password policies elements, such as management, complexity, and password alternatives (multifactor authentication, certificates, and biometrics)
5.5 Describe remote access and site-to-site VPNs
5.6 Configure and verify access control lists
5.7 Configure Layer 2 security features (DHCP snooping, dynamic ARP inspection, and port security)
5.8 Differentiate authentication, authorization, and accounting concepts
5.9 Describe wireless security protocols (WPA, WPA2, and WPA3)
5.10 Configure WLAN using WPA2 PSK using the GUI
Automation and Programmability
O tópico 6 dessa certificação traz as maiores novidades e assuntos muito esperados pela galera de Infra de Redes.
Você enfrentará questões sobre redes baseadas em controladores, software-defined networks (SDN), network programmability, REST-based APIs (CRUD, HTTP verbs e data encoding), Cisco DNA Center, Puppet, Chef e Ansible.
Os seguintes itens fazem parte desse tópico (em negrito são novidades em relação do CCNA 200-125):
6.0 Automation and Programmability
6.1 Explain how automation impacts network management
6.2 Compare traditional networks with controller-based networking
6.3 Describe controller-based and software defined architectures (overlay, underlay, and fabric)
6.3.a Separation of control plane and data plane
6.3.b North-bound and south-bound APIs
6.4 Compare traditional campus device management with Cisco DNA Center enabled device management
6.5 Describe characteristics of REST-based APIs (CRUD, HTTP verbs, and data encoding)
6.6 Recognize the capabilities of configuration management mechanisms Puppet, Chef, and Ansible
6.7 Interpret JSON encoded data
Onde Posso Ter Mais Informações sobre o CCNA 200-301 na DlteC?
Além disso, o CCNA atual que está dividido nos cursos CCNA CCENT e CCNA ICND-2 serão atualizados e teremos (se já não tivermos quando você estiver londo esse artigo) a versão atualizada para o CCNA 200-301.
Então vamos finalizando o artigo por aqui, parabéns se você leu até aqui e me acompanhou até o final…
… saiba que você está de parabéns por isso!
Muito obrigado e até um próximo artigo.
Ah, já ia esquecendo… se você gostou do artigo compartilhe com seus amigos, grupos e redes sociais, nos ajude a divulgar conhecimento com a galera da área de Infra de Redes.
E se você tem alguma dúvida, comentário ou até mesmo um elogio utilize o campo de comentários que tem descendo a página!
Nesse artigo vamos falar sobre alguns problemas que uma rede sem fio pode ter e dois deles vamos falar com mais detalhes, que são a perda no espaço livre e a absorção do sinal wireless.
Como o sinal de RF trafega em espaço aberto, ou seja, via ondas eletromagnéticas pelo ar, ele está sujeito a muito mais tipos de interferências, atenuações e problemas que um sinal elétrico que passa por um cabo UTP ou um sinal óptico através de um cabo de fibra.
Portanto, esse tópico é dedicado ao estudo dos principais problemas que um sinal sem fio enfrenta e suas consequências.
Basicamente os sinais sem fio estão
sujeitos aos seguintes efeitos que podem atenuar (diminuir a potência do
sinal), distorcer, interferir ou afetar as transmissões sem fio:
Perda no espaço livre
Absorção (Penetração)
Reflexão
Refração
Espalhamento do sinal
Propagação multicaminhos
Os problemas que serão apresentados a seguir causam distorções, atenuações, degradação e até em alguns casos o cancelamento do sinal na recepção.
Esses problemas podem ser avaliados e minimizados com o “site survey”.
O sitesurvey é uma visita técnica onde pessoas qualificadas irão analisar o ambiente inserindo APs de prova para coletar informações sobre o sinal e ao final do processo se tem um relatório com o posicionamento que cada AP deve ter para garantir o sinal na área de cobertura escolhida pelo administrador de redes.
Além do posicionamento, muitas vezes teremos também recomendações de tipos de antenas a serem utilizadas, potência dos equipamentos e demais requisitos para que o modelo de AP possa ser especificado.
Agora vamos falar mais sobre os dois problemas que citamos no começo do artigo.
Perda no Espaço Livre
Apenas parte da energia transmitida através das ondas eletromagnéticas é captada pela antena receptora, sendo que a perda é maior quanto maior for a distância percorrida pelo sinal.
Esta perda é denominada Perda no Espaço Livre ou Free Path Loss.
Nesse caso não estamos considerando nenhum anteparo entre o emissor e o receptor, por isso o nome “espaço livre”.
Depois veremos que ao inserir anteparos ou obstáculos outros problemas são adicionados à perda em espaço livre, causando mais atenuações e distorções no sinal original emitido pelo transmissor.
Imagine uma pedra jogada no meio de um lago sem ondulações, do ponto onde a pedra foi jogada para a margem as cristas das ondas vão ficando menores, ou seja, quanto mais perto de onde jogamos a pedra maior será a crista da onda ou sua amplitude.
Esta mesma analogia podemos fazer para as emissões de uma antena de um AP, quanto mais perto do AP mais forte será o sinal, ou seja, a onda eletromagnética emitida pelo AP diminui de potência à medida que nos afastamos dele.
Perda por Penetração ou Absorção
Quando um sinal atravessa um objeto, ou seja, um obstáculo entre a origem e destino da comunicação, este sinal sofre com uma redução do seu nível de potência (atenuação).
Esta perda da potência do sinal ao cruzar os objetos é chamada de perdas de penetração ou absorção.
A perda de penetração depende do material o qual compõe o objeto.
Obstáculos como paredes e janelas, por exemplo, apresentam valores diferentes de perdas de penetração.
Quanto mais metal estiver presente no obstáculo, maior será a perda por absorção.
Como Aprender Mais sobre Redes Sem Fio com a DlteC?
Esse artigo foi feito com base no curso Wireless LANs (Redes sem Fio).
Nesse treinamento você vai aprender os conceitos de funcionamento, tecnologias, principais problemas de transmitir em espaço aberto, tipos de redes sem fio e suas topologias, transmissão de dados em redes sem fio, padrões IEEE 802.11, princípios de segurança, como realizar um site survey e como aplicar tudo isso com um super exemplo prático (aula bônus).
Se você já é nosso assinante Premium basta acessar o Portal, ir no Menu cursos e ativá-lo para estudar.
Se você ainda não é assinante, por fazer um testdrive e conhecer alguns capítulos do curso sem compromisso, basta criar um usuário no Portal, ir no menu Cursos e ativar seu testdrive, simples assim.
Com isso finalizamos mais um artigo sobre redes sem fio e esperamos que seja útil.
Não esqueça que se você tiver dúvidas ou sugestões temos um campo para isso bem aqui no final do artigo, é só descer a página para ter acesso!
Você já ouviu falar nesse termo MAC Flooding ou MAC Address Table Overflow? Não tem nada a ver com McDonalds, isso eu posso garantir (brincadeira só para descontrair rsrs).
O MAC Flooding ou MAC Address Table Overflow é uma ameaça básica que não precisa nem de um especialista em segurança para ser resolvido.
Na realidade com configurações básicas e poucas linhas de comando esse problema já estará resolvido… e TODO profissional de Infra de Redes deveria conhecer essa ameaça.
Você deve estar se perguntando: Mas o que eu preciso saber então? É tanta coisa…
Realmente, mas construir o conhecimento em Redes ou Infraestrutura de TI é como construir uma casa…
… O INÍCIO É PELA BASE.
Um ataque simples como o MAC Flooding, que um CCENT (um profissional nível de entrada) pode resolver, pode transformar um switch em um Hub e permitir uma espionagem na rede ou VLAN atacada.
Isso pode te custar sua reputação ou até mesmo o emprego se, por exemplo, conseguirem capturar informações da diretoria da empresa.
Exagero? Posso estar assustando um pouco… mas isso é possível sim!
Endereços MAC
O endereço MAC é a principal forma de identificação de
equipamentos em uma rede, e são utilizados em redes Ethernet, Wireless
(802.11a/b/g), Bluetooth, FDDI, Fiber Channel e Token Ring.
Os endereços MAC possuem 48 bits, sendo que os primeiros 24 bits são utilizados para identificar o fabricante da placa de rede e são definidos pelo IEEE.
Já os últimos 24 bits são atribuídos pelo fabricante da placa.
Para que os endereços MAC funcionem adequadamente eles devem ser únicos dentro de uma rede, caso haja mais de um haverá conflito.
Por definição o endereço FF-FF-FF-FF-FF-FF é usado como endereço de broadcast, ou seja, servirá para comunicação simultânea com todas as máquinas que estão na mesma rede.
Entendendo a Tabela de Endereços MAC e Encaminhamento de Quadros
As atividades básicas de um switch são relativamente simples, pois ele precisa:
Aprender MACs de origem para formar uma tabela de encaminhamento ou tabela de endereços MAC
Encaminhar ou filtrar os quadros entre as portas (processo de comutação)
Evitar Loops de camada-2 ou L2 (layer 2)
A tabela de endereços MAC ou CAM Table (Content Addressable Memory) de forma geral armazena o endereço do computador que está conectado a cada uma das portas do switch.
Além disso, a tabela de endereços MAC armazena outras informações, tais como o número da VLAN que a porta está vinculada e a quanto tempo esse endereço foi aprendido.
Os endereços MAC normalmente são aprendidos de forma dinâmica e tem um “tempo de vida” padrão na tabela de endereços MAC de 300 segundos ou cinco minutos.
Se o computador conectado a determinada porta não enviar mais quadros a informação é apagada depois dos 300 segundos, assim o switch vai eliminando endereços de computadores que foram desligados ou desconectados da rede.
Nesse processo de encaminhamento o switch quando recebe um quadro ele pode conhecer ou não a porta de destino para encaminhá-lo.
Caso ele conheça o quadro será enviado para a porta de destino e se não conhecer faz o processo de flooding ou inundação.
O flooding simplesmente é o encaminhamento do quadro para TODAS as portas do switch, menos para a porta onde o quadro foi recebido, pois não teria sentido, certo?
Portando, em condições normais de temperatura e pressão a comunicação entre as portas dos switches são realizadas ponto a ponto e no máximo um quadro é recebido pelas outras portas, quando o switch ainda desconhece o destino.
Em um Hub isso não ocorre desse jeito, pois um quadro recebido é copiado para todas as portas, não importando se o PC de destino está ou não conectado nela.
Essa é uma das vantagens do switch, essa segmentação realizada entre as portas e a impossibilidade de espionar o tráfego dos demais usuários do dispositivo, certo?
Mas você sabia que a tabela de endereços MAC tem limite?
Você deve estar pensando: “Opa, como assim?”
Normalmente em um switch não modular de 24 ou 48 portas a tabela de endereços MAC varia de 6000 a 8000 endereços, podendo ser um pouco mais ou um pouco menos dependendo do fabricante e linha de switch.
E o que ocorre se lotar essa tabela de endereços e não tiver mais espaço para gravar novas entradas de MACs?
O que ocorre é o estouro da tabela de endereços MAC e os endereços mais antigos são apagados para gravar os mais novos.
E é nesse comportamento que o “espertão” inventou um jeito de transformar um switch em um hub! Vamos ver como a seguir.
Como Funciona o MAC Flooding
Já vimos que switch constrói e mantém dinamicamente uma tabela CAM (Content-Addressable Memory) ou tabela de endereços MAC (MAC Adrress Table), certo?
Essa tabela então contém todas as informações sobre o MAC necessárias para cada porta.
A memória CAM é o equivalente no switch à tabela de roteamento dos roteadores, porém como já vimos ela tem um limite.
É a partir das informações armazenadas na tabela CAM que o switch escolhe para qual porta um determinado quadro deve ser encaminhado.
Um dos principais problemas de segurança envolvendo o endereçamento da camada de enlace é o overflow da tabela CAM dos switches ou MAC Flooding.
A tabela CAM de um switch é responsável por armazenar e relacionar endereços MAC, portas e parâmetros de VLANS, podendo assim encaminhar de forma correta os quadros que passam por ele.
Fisicamente a tabela CAM é armazenada em uma memória normal e como tal possui tamanho limitado, percebendo isso no ano de 1999 Ian Vitek criou uma ferramenta chamada Macof, que cria inundações de endereços MAC de origem inválidos (cerca de 155000 por minuto).
Essa ferramenta é capaz de encher rapidamente a tabela CAM do switch que está diretamente conectado ao host responsável pela execução da ferramenta, e os switches que estiverem conectados ao equipamento atacado também são afetados.
O resultado desse ataque é um comportamento adotado pelo switch quando ele não consegue encontrar um endereço em sua tabela, ele envia os quadros recebidos para todas as suas portas, passando a se comportar como um Hub, conforme figura a seguir.
Com esse comportamento é possível realizar a espionagem dos pacotes e até possibilitar um ataque de man-in-the-middle monitorando o tráfego da rede.
Como Evitar o MAC Flooding ou CAM Table Overflow?
Para resolver esse problema é preciso utilizar switches gerenciáveis que possuam ferramentas de segurança para controlar os dados que trafegam em cada porta.
Normalmente o administrador define um número máximo de endereços MAC que podem ser aprendidos de forma segura em cada uma das portas dos switches.
Quando um software como o Macof tenta gerar MACs falsos e aleatórios esse máximo é atingido, portanto uma ação de segurança pode ser tomada.
Por exemplo, você define um máximo de 5 MACs seguros aprendidos por porta, quando o sexto MAC for gerado ele pode ser filtrado ou então a porta simplesmente pode ser desligada e gerar uma mensagem de erro para o gerenciamento de redes.
Esse ataque também pode ser mitigado com o uso do port security em switches Cisco (outros fabricantes possuem recurso similar).
Esse comportamento de encaminhar os quadros cujo endereço não é conhecido, chamado de flooding ou inundação, ou quando a tabela CAM está cheia para todas as portas (menos para a própria porta que encaminhou o quadro) é chamado de modo fail-open ou falha aberta.
No modo fechado ou fail-closed o comportamento seria o contrário, ou seja, o equipamento não encaminharia esse tipo de quadro que ele não saberia encaminhar, porém no caso dos switches isso não é possível de se configurar.
Como eu Posso Aprender Mais sobre Configurações Seguras de Switches e Evitar o Mac Flooding na DlteC do Brasil?
O MAC Flooding ou CAM Table Overflow é tradado nos cursos das certificações:
CCNA CCENT
CCNA Security
CCNA 200-301
CCNP SWITCH
Nós vamos manter os cursos das versões retiradas pela Cisco por um tempo indeterminado, isso porque nossos alunos assim que souberam da mudança já vieram nos pedir.
Então como nós gostamos de ver nossa galera feliz, vamos manter os cursos!
Então vamos finalizar o artigo, parabéns se você leu até aqui e me acompanhou até o final…
… saiba que você está de parabéns por isso!
Muito obrigado e até um próximo artigo.
Ah, já ia esquecendo… se você gostou do artigo compartilhe com seus amigos, grupos e redes sociais, nos ajude a divulgar conhecimento com a galera da área de Infra de Redes.
E se você tem alguma dúvida, comentário ou até mesmo um elogio utilize o campo de comentários que tem descendo a página!
O mercado de TI no Brasil nunca experimentou tamanha
expansão. Segundo pesquisas recentes, este setor demandará mais de 400 mil novos
empregos até 2024 e onde a certificação
LINUX LPIC-1 poderá entrar nesta equação para ajudar em sua carreira?
É sobre isso que
vou tratar neste artigo! Por isso, fique comigo até o final, combinado?
Porque Linux?
Deixa eu começar com algumas estatísticas mostram o quanto é importante você aprender a trabalhar com o Linux o mais rápido possível:
Em
2019, todos os 500 supercomputadores do mundo operaram com o Linux.
Diversas
potências da tecnologia trabalham rotineiramente com o Linux, incluindo Google, NASA, Facebook, Amazon e Microsoft (isto
mesmo!).
Cerca de 96,5% dos servidores que suportam os principais domínios do mundo rodam em Linux.
Mais de 90% de toda a infraestrutura em cloud opera em Linux.
Somente essas estatísticas justificariam a necessidade de entender e aprender a trabalhar com esse sistema operacional tão importante no mundo da Tecnologia…
… e nem citamos a Internet das Coisas (IoT – Internet of Things)!
Qualificação Profissional e a Certificação Linux LPIC-1
Mais do que
nunca, a busca pela qualificação se tornou um elemento indispensável a qualquer
profissional que deseja ingressar e, especialmente, continuar ativo neste
mercado caracterizado pela dinamicidade.
Mesmo com um
diploma acadêmico de impacto, muitas vezes o profissional não se encontra
preparado para as “encrencas” que o esperam no mercado, já que novas
tecnologias surgem em uma velocidade impressionante.
E neste panorama,
entram em cena as certificações profissionais,
cujo intuito primário é preencher esta lacuna:
“Preparar os profissionais com as habilidades
exigidas pelo mercado de trabalho.”
Uma das mais
sólidas e respeitadas certificações são aquelas oferecidas pelo instituto
canadense Linux Professional Institute – LPI.
Como muitas das
tecnologias emergentes possuem o Linux
como base, as certificações neste sistema operacional são cada vez mais
valorizadas.
Tendo certificado
milhares de candidatos espalhados pelo globo desde a década de 1990, os exames
do LPI buscam avaliar habilidades
imprescindíveis ao profissional desejante atuar com ServidoresLinux.
Na base de sua
pirâmide de certificações profissionais, encontramos a certificação Linux LPIC-1 – “Administrador
Linux”.
Como é
responsável por estabelecer uma base sólida de conhecimentos imprescindíveis
sobre o Linux, esta certificação é Linux
LPIC-1 é uma das mais desejadas no
mundo inteiro.
Dentre os
objetivos presentes nos dois exames requeridos para a sua conquista, o
candidato terá contato com a arquitetura geral do sistema, com as diferentes
formas de gestão de pacotes, aplicação prática de comandos administrativos,
integração de máquinas em rede, critérios essenciais sobre segurança, dentre
outros assuntos.
Tirei um pedaço
do site oficial do Linux Professional Institute que é muito interessante, onde
informa que, para se tornar certificado Linux LPIC-1, o candidato (você futuramente) deve ser capaz de:
Entender
a arquitetura de um sistema Linux;
Instalar
e manter uma estação de trabalho Linux, incluindo X11 e configurá-lo como um
cliente de rede;
Trabalhar
na linha de comandos do Linux, incluindo comandos GNU e Unix comuns;
Lidar
com arquivos e permissões de acesso, bem como segurança do sistema; e
Executar
tarefas de manutenção fáceis: ajudar os usuários, adicionar usuários a um
sistema maior, fazer backup e restaurar, desligar e reinicializar.
E para ser bem
sincero, o pessoal da LPI resumiu bastante, porque você irá aprender muito mais
ao estudar o conteúdo da certificação Linux
LPIC-1 se nos escolher como parceiros de estudo!
E mais um motivo
legal para a escolha da certificação Linux LPIC-1
é que ela está disponível em nossa língua nativa, o Português, pois sei que
idioma de prova assusta ainda muita gente e esta é uma super-vantagem da
certificação Linux LPIC-1!
Por esta e outras
razões, a certificação Linux LPIC-1
é muito bem vista no mercado pelos empregadores, já que demonstra que o seu
candidato está realmente comprometido com a carreira e que passou por um
processo rigoroso de exames.
O aspecto
financeiro também é um atrativo, pois muitas empresas costumam oferecer bônus a
profissionais certificados.
A razão é simples: as empresas sabem que estarão contratando (ou promovendo) um profissional que está antenado com o que está acontecendo.
Um profissional
que buscou proativamente a chancela de um instituto sério para validar as suas
habilidades e, consequentemente, seus ativos (servidores e desktops Linux) estarão em boas mãos.
A certificação
Linux LPIC-1 também irá proporcionar
ao profissional a sua integração em uma comunidade global de outros
profissionais qualificados.
Com isso, suas
experiências poderão ser compartilhadas, novos conhecimentos serão adquiridos
e, o mais importante: você poderá inspirar outros profissionais ….
… e isto não tem valor a ser calculado! É você como REFERÊNCIA!
Inicie também
conosco sua jornada em direção ao mundo Linux e depois me conte suas
experiências!
Certificação Linux LPIC-1 no Portal da DlteC
No portal da DlteC a certificação LPIC-1 está dividida em duas Trilhas ou Cursos:
Todo conteúdo já está atualizado para a versão 5 do LPIC-1, seguindo todas as orientações publicadas no site oficial da LPI.
No curso Linux LPI 101-500 você vai estudar a arquitetura do Sistema Linux (tópico 101.1), instalação do Linux e gerenciamento de pacotes (tópico 101.2), comandos do Linux e Unix (tópico 101.3), assim como os dispositivos, sistemas de arquivos do Linux e FHS (tópico 101.4).
Já no curso Linux LPI 102-500 você vai estudar o Shells e Scripts do Shell para Linux (105), Interface de Usuários e Desktops (106), Tarefas Administrativas no sistema (107), Serviços Essenciais (108), Fundamentos de Redes com foco em Linux (109) e também tópicos de Segurança em Linux (110).
Todo conteúdo utiliza nossa didática e metodologia testada e comprovada com nossos alunos e assinantes.
Você vai estudar e aprender o conteúdo através de vídeo aulas, materiais de leitura, simulados e praticar a linha de comando seguindo as instruções que passamos durante o curso.
Você pode ter mais detalhes dos cursos nos links abaixo:
Subrede e Máscaras de Subrede é um assunto complexo ou não na sua opinião?
Se eu te der para calcular qual a máscara de subrede devemos utilizar para atender uma rede com 50 computadores, por exemplo, você saberia calcular sem utilizar um “subnet calculator tabajara”? Ou até mesmo uma calculadora normal?
Ou então se você tivesse que descobrir se a rota da rede do host 10.0.100.200/23 está na tabela de roteamento do seu roteador? Você saberia a partir do IP e da máscara de subrede descobrir qual a subrede que deveria procurar na tabela de roteamento do roteador em questão?
O assunto IPv4 (IP versão 4), máscaras de subrede, divisão em subredes tem sido deixado de lado por muitas pessoas porque o IPv6 está entrando e vai “matar” o IPv4…
… parece até fase de vídeo game onde o IPv6 tem que matar o chefão IPv4 (rsrs).
Mas se você nos acompanha a um tempo sabe que não é bem assim e que desde 2012 isso vem sido dito, que o IPv4 vai morrer, mas até agora temos no Brasil aproximadamente 32% de adesão do IPv6.
Por isso mesmo, se você não sabe como um endereço IPv4 funciona e muito menos como calcular uma subrede deve sim se preocupar e aprender, pois isso é a base de uma rede.
Lembre-se: Um bom projeto de Redes nasce da topologia e Endereçamento!
IPv4, Classes e Máscaras de Subrede
Tradicionalmente os endereços IPv4 são divididos em Classes, sendo que as três primeiras utilizamos para “navegar” nas Intranets e Internet:
Classe A (/8 ou 255.0.0.0): 0.0.0.0 a 126.255.255.255
Classe B (/16 ou 255.255.0.0): 128.0.0.0 a 191.255.255.255
Classe C (/24 ou 255.255.255.0): 192.0.0.0 a 223.255.255.255
Classe D: 224.0.0.0 a 239.255.255.255
Classe E: 240.0.0.0 a 255.255.255.255
Dentro dessa faixa de endereços existem diversos que são reservados ou não são utilizados, por exemplo, na prática a classe A vai se 1.0.0.0 a 126.255.255.255, pois as redes 0.0.0.0 e 127.0.0.0 são reservadas para uso especial.
Porque Utilizar Subredes?
Imagine que tudo fosse como era nos primórdios da Internet, se pegarmos a faixa de endereços classe A temos apenas 126 redes úteis, pois as redes 0.0.0.0 e 127.0.0.0 não podem endereçar hosts e computadores na rede.
Cada Rede Classe A tem a possibilidade de ter aproximadamente 16 milhões de hosts.
Com isso teríamos apenas 126 empresas gigantescas ocupando uma classe inteira de endereços!
Com certeza a Internet não existiria faz tempo, seria monopólio dessas empresas, concorda?
Por isso mesmo os conceitos de subrede juntamente com o “classless” foram adotados na prática na Internet IPv4 atual.
Na prática não temos mais “classes” na Internet e sim uma rede e um prefixo que eu posso dividir conforme necessidade do provedor de serviços.
O que é Dividir em Subredes?
Dividir uma rede em subredes nada mais é que utilizar máscaras de subrede menores que o padrão, ou seja, vamos “emprestar” bits na máscara de subrede que seriam de Hosts para criar as Subredes.
Por exemplo, uma rede classe C tem 24 bits de rede e 8 bits de host, ou seja, 255.255.255.0 = 11111111.11111111.11111111.00000000.
Os bits 1s das máscaras de subrede representam a porção de Rede ou Subrede, já os bits zero representam o conjunto de hosts que aquela rede pode ter.
Em uma rede 192.168.1.0/24 a rede é 192.168.1.0 (primeiro bit da sequência) e temos a variação dos bits de host de 0 a 255:
192.168.1.0 (00000000)
192.168.1.1 (00000001)
192.168.1.2 (00000010)
…
192.168.1.254 (11111110)
192.168.1.255 (11111111)
Se emprestarmos 1 bit da máscara de subrede, onde seria o primeiro bit de host, teremos essa rede dividida em duas subredes:
192.168.1.0/25 (192.168.1.00000000)
192.168.1.128/25 (192.168.1.10000000)
Os hosts agora serão a variação dos 7 bits que restaram da máscara original, portanto ficaremos com 126 hosts em cada uma das subredes, pois o primeiro IP é a subrede e o último é o endereço de broadcast.
No artigo abaixo você pode ver TODAS as subredes IPv4 possíveis:
Portanto temos as subredes iniciando em 172.16.0.0 e terminando em 172.16.254.0, sendo que elas variam de dois em dois:
172.16.0.0
172.16.2.0
172.16.4.0
…
172.16.252.0
172.16.254.0
E aqui vem algo que confunde e até surpreende muita gente, pois temos endereços com final zero ou 255 que não são nem subrede nem broadcast!
Veja que para sair de 172.16.0.0 e chegar na segunda subrede 172.16.2.0 temos: 172.16.0.1, 172.16.0.2, 172.16.0.3… 172.16.0.254, 172.16.0.255, 172.16.1.0, 172.16.1.1… 172.16.1.254 até 172.16.1.255.
Veja que encrenca acima, normalmente endereços finais zero e 255 já marcamos como rede/subrede e broadcast… quase sem pensar!
Além disso, dividir subredes abaixo de 24 bits não é tão simples como as tradicionais /24, /25 e acima que são sempre com faixas de endereço contínuos.
Claro que você deve estar pensando… “Eu uso o subnet calculator e que se lasque” (rsrsrs).
Mas e em uma entrevista de emprego, prova de certificação ou até mesmo concurso público que não permite esse tipo de recurso extra?
Onde você tem “papel e caneta” mais a ajuda do seu cérebro! Como eu lido com esse tipo de situação?
Como Resolver esses Problemas e Aprender IPv4 e Cálculo de Subredes?
Primeiro entenda e decore as classes de endereços, máscaras padrões e faixas de endereços IPv4, incluindo os principais como a RFC1918, Internet (0.0.0.0) e Loopback (127.0.0.0).
Segundo você deve aprender a converter de binário para decimal e o contrário com números de 8 bits que vão de 0 a 255 em decimal… Porque?
Porque o IPv4 tem 32 bits, é escrito em 4 bytes (4 conjuntos de 8 bits) e em decimal pontuado.
Terceiro você deve aprender uma metodologia para calcular subredes, alguma fórmula ou método claro, simples e eficiente.
Não adianta utilizar métodos que dependam de calculadora, por exemplo, pois se você não puder utilizar ou não tiver esse recurso em mãos vai ficar paralisado quando precisar lidar com tal tipo de problema, simples assim.
Quarto e mais importante: pratique exaustivamente até dar o “clique” no seu cérebro e você entender realmente o que está acontecendo… como resolver… porque resolver “assim ou assado”… que técnica utilizar em cada tipo de problema ou situação prática.
A PRÁTICA LEVA A PERFEIÇÃO! E te ajuda a fixar o conhecimento de verdade!
Dois Cursos para você Mudar de Nível em Endereçamento IPv4 e Subredes!
Temos dois cursos ótimos que você pode fazer em nosso Portal para solidificar seus conhecimentos em Endereçamento IPv4 e Máscaras de Subredes:
Com o primeiro curso sobre Endereçamento IPv4 e Classes você vai aprender a base do que é um endereço IP, binário para IP, classes de endereços (A, B, C, D e E) e tipos de endereços IP versão 4.
Já no curso Subredes Ninja você vai aprender a calcular sub-redes IP para classes A, B e C com diversas máscaras, prefixos e níveis de complexidade diferentes utilizando a técnica ninja que eu desenvolvi durante meus anos de ensino e vida prática como profissional certificado CCNA e CCNP.
Ambos os cursos são ótimos para quem está se preparando para provas de certificação, concursos públicos na área de Infraestrutura de TI e Redes de Computadores, assim como fazendo faculdade na área de Redes ou Sistemas de Informação.
Então vamos finalizar o artigo, parabéns se você leu até aqui e me acompanhou até o final…
… saiba que você está de parabéns por isso!
Muito obrigado e até um próximo artigo.
Ah, já ia esquecendo… se você gostou do artigo compartilhe com seus amigos, grupos e redes sociais, nos ajude a divulgar conhecimento com a galera da área de Infra de Redes.
E se você tem alguma dúvida, comentário ou até mesmo um elogio utilize o campo de comentários que tem descendo a página!
Primeira coisa que queria deixar claro: Vamos lançar um curso para o a certificação Cisco CCNA 200-301 ou atualizar o que temos no Portal da DlteC? A resposta é…
… NÓS VAMOS LANÇAR UM MATERIAL NOVO CHAMADO TRILHA CCNA 200-301.
Os cursos CCNA CCENT (ICND-1 ou 100-105) e CCNA ICND-2 (200-105), que são os conteúdos do CCNA 200-125 serão mantidos no Portal porque diversos alunos pediram e por terem conteúdo que será retirado nessa nova versão.
Nesse artigo vou conversar um pouco das “mudanças” e comparar o CCNA Routing and Switching atual (prova 200-125 ou 100-105+200-15) com o novo (mas não tão novo) 200-301.
Pré-Requisitos do CCNA 200-301 em relação ao 200-125
Na versão do CCNA R&S (Routing and Switching) você tinha duas opções de prova, sendo que em duas provas, a primeira delas chamada ICND-1 ou certificação CCENT, o candidato poderia ser iniciante e nunca ter tido contato com dispositivos Cisco.
Na versão 200-301 do CCNA a Cisco recomenda que o candidato tenha um ou mais anos de experiência com implementação e administração de dispositivos Cisco ou soluções Cisco.
Nesse caso específico as soluções são com roteadores, switches, access points e controladoras sem fio, além disso contato com a linha de comando desses equipamentos.
Também é recomendado conhecimento básico em endereçamento IP, principalmente IPv4, e também conhecimento dos fundamentos de Rede.
Se você é também um aficionado por Cisco vai entender que essa mudança é bem radical!
Apesar de todas as carreiras agora não exigirem certificações prévias isso não significa que você não precise de uma base.
O novo CCNA 200-301 removeu dos tópicos do exame ou blueprint o Modelo de Referência OSI, aí você pode pensar…
… “Então isso nem preciso estudar porque não vai cair! Oba!”
Não é bem assim… todos os dispositivos de Rede são classificados em relação ao modelo OSI, então indiretamente você pode ter uma questão que tenha nomenclatura que se refira a essa classificação na prova.
Isso é só um exemplo para que você entenda que o que muda é deixar de existir o PRÉ-REQUISITO FORMAL, mas isso não tira a necessidade de você saber esses conteúdos!
Tipos de Questões do Cisco CCNA 200-301 em relação ao Exame 200-125
Aqui não muda nada, teremos ainda as famosas questões de:
Múltipla escolha com uma opção ou múltiplas opções
Drag and Drop (escolher e arrastar)
Simlet (mistura de simulador com perguntas de múltipla escolha)
Testlet (cenário com várias perguntas)
Simulation (uso de simulador para implementação ou troubleshooting)
Fill-in-the-blank (preencher com a resposta – muito rara de cair)
Então continuamos com teoria e prática, você precisa treinar com simuladores ou equipamentos reais os comandos da CLI que fazem parte do blueprint.
Conteúdo e Peso do CCNA 200-301 versus CCNA R&S
Nas imagens abaixo você vai notar as principais diferenças e pesos nas provas.
Note que no CCNA 200-125 ou CCNA R&S 59% da prova está nos fundamentos de Redes, switching e roteamento.
Por incrível que pareça aumentou no Cisco CCNA 200-301, agora passou para 65% da prova!
Na verdade apenas 30% da prova nova 200-301 será realmente conteúdo novo ou diferente do CCNA 200-125.
Esse conteúdo novo foram trazidos do CCNA Wireless, CCNA Security e novidades sobre automação e programabilidade de Redes.
Esse assunto “Programação” ou “Programabilidade de Redes” vem assustando muitos alunos e profissionais interessados no CCNA, muita gente tem se perguntado:
“Vou ter que saber programar para fazer o Cisco CCNA 200-301?“
A resposta é não… você vai aprender os conceitos de automação, principais ferramentas, aprender a ler e interpretar alguns formatos utilizados e como se comunicar via API utilizando o REST.
Então se você já fez o CCNA R&S, seja ele em uma ou duas provas, vai precisar estudar relativamente pouco para se atualizar.
E vale a pena esse estudo? COM CERTEZA!
Você pode ver também o conteúdo detalhado do 200-301 no artigo abaixo:
Então ficamos por aqui, parabéns se você leu até aqui e me acompanhou até o final saiba que você está de parabéns por isso!
Muito obrigado e até um próximo artigo.
Quero pedir um favor: se você gostou do artigo compartilhe com seus amigos, grupos e redes sociais, nos ajude a divulgar conhecimento com a galera da área de Infra de Redes.
E se você tem alguma dúvida, comentário ou até mesmo um elogio utilize o campo de comentários que tem descendo a página!
Olá caro leitor, como você já deve saber a trilha de cursos para a certificação Linux LPIC-1 foi lançada a pouco tempo e estamos agora em fase final para o lançamento dos cursos da trilha para a certificação Linux LPIC-2.
Por isso mesmo vou falar um pouco dessa jornada entre ser LPIC-1 e o salto que a LPIC-2 pode te ajudar a dar em relação aos seus conhecimentos e oportunidades no mundo Linux!
Crescer profissionalmente e conquistar uma excelente remuneração são alguns dos objetivos mais ouvidos na pluralidade dos diálogos cotidianos.
Tendo o mercado
de TI como ponto focal para uma
breve análise, apesar de caracterizado pela dinamicidade feroz e, por
conseguinte, trazer uma série de desafios, trata-se de uma das poucas áreas
onde a excelência e a sapiência são determinadores de empregabilidade.
Neste cenário
louco, mas recompensador em muitos casos, é observável o crescimento
exponencial das tecnologias open source,
responsáveis por movimentar bilhões e bilhões de dólares por ano.
Neste ínterim, o Linux age como “tecnologia-mãe”
a muitas delas. Devido a esta constante influência, algumas perguntas pairam no
ar. Neste momento, tomo a liberdade para fazer algumas:
“Como posso ascender os meus conhecimentos em Linux para acompanhar esta realidade?”.
“Quais as preocupações devo levar em conta na decisão que tomarei?”.
Este artigo visa examinar essas questões. Portanto, fique comigo até o final.
A Certificação Linux LPIC-2
A certificação
profissional LPIC-2: Linux Engineer,
do Linux Professional Institute (LPI)
é uma das mais bem vista no mercado de trabalho por diferentes motivos.
O primeiro deles,
sob o ponto de vista do empregador, indica que o candidato quis algo mais…
foi avaliado por uma entidade canadense séria em relação a tecnologias e
procedimentos administrativos que fazem parte da rotina do “chão da TI“.
Trazendo esta
análise para o lado do profissional, este também é beneficiado pelos
“saltos” qualitativo e quantitativo que dará em relação à bagagem
intelectual a ser aplicada na administração do Linux.
Enquanto a
certificação LPIC-1 oferece a base
sólida necessária ao compreendimento geral do sistema, a LPIC-2 vai além e posiciona o profissional frente a frente com tecnologias
e procedimentos que irá experimentar no mercado.
Isto poderá ser
facilmente identificado ao analisar os objetivos dos dois exames necessários a
conquista desta certificação.
Sendo assim,
durante os preparativos, o candidato poderá estudar assuntos relevantes
diversos, como compilação e instalação do kernel, configurações de RAID, tecnologias como BIND, Apache, Nginx, Samba…
… dentre muitas outras.
O trecho a seguir
foi destacado a partir do site oficial do LPI,
onde são destacadas as competências exigidas a um profissional certificado LPIC-2:
Executar
administração avançada do sistema,
incluindo tarefas comuns relacionadas ao kernel
do Linux, inicialização e manutenção do sistema;
Executar
gerenciamento avançado de armazenamento em block e sistemas de arquivos, bem
como redes avançadas e autenticação e segurança do sistema, incluindo firewall e VPN;
Instalar
e configurar serviços de rede fundamentais, incluindo DHCP, DNS, SSH, servidores Web, servidores de
arquivos usando FTP, NFS e Samba, entrega de e-mail;
Supervisionar
os assistentes e assessorar a gestão em automação
e compras.
O aspecto financeiro é também importante de ser destacado.
No site do LPI, é destacado que um profissional certificado LPIC-2 tem chances de obter bônus de mais de 30% em suas remunerações.
Tomar a decisão
de prosseguir os estudos sobre Linux
é algo merecedor de louvor e de extrema importância para o seu desenvolvimento
profissional. Portanto, caso esteja nesta “vibe”, endosso-a com os
meus cumprimentos.
Alguns outros pontos também precisam ser aqui destacados para que você esteja realmente alinhado com o que lhe espera.
A primeira coisa é em relação ao idioma dos exames.
Neste momento, esses poderão ser realizados em Inglês, Alemão ou Japonês.
Portanto, isto requer uma preparação à parte, já que é preciso estar “afiado” em alguma delas para que não passe “perrengue” em interpretar as questões no dia do exame.
Mas assim como para outras provas, o inglês aqui é de leitura e interpretação de texto, não precisa ser pós-graduado em Oxford para fazer a prova!
O que o Mercado Espera de um Profissional Certificado Linux LPIC-2?
Outra questão importante é que, ao tornar-se certificado LPIC-2, isto gerará uma expectativa muito maior por parte do mercado geral em relação a suas habilidades profissionais. O que gera, portanto, um um grande desafio!
Portanto, é
necessária a criação de bons hábitos para conseguir “sugar” o máximo
de aprendizado durante os seus preparativos rumo a conquista da certificação.
Isto inclui a
leitura criteriosa e constante de manuais de comandos, documentações de
programas e, sobretudo, da prática intensa e rotineira do que você irá aprender
– processo este que denominei como “Kata Linux”.
Se for preciso,
crie 5, 10, “n” máquinas virtuais para testar cenários, possibilidades,
perceber nuances…
…o intuito principal é: além de tornar-se certificado LPIC-2: Linux Engineer, você irá realmente estar à frente de muitos outros candidatos a uma determinada oportunidade.
Isto é uma vantagem competitiva que você levará consigo…
… e para qualquer lugar!
Este é o “algo a mais” resultante do processo de preparação para os exames rumo a certificação LPIC-2: Linux Engineer.
Inicie também conosco a sua jornada rumo à certificação LPIC-2 e depois me conte suas experiências!
Então vou ficando por aqui, parabéns se você leu até aqui e me acompanhou até o final…
… saiba que você está de parabéns por isso!
Muito obrigado e até um próximo artigo.
Ah, já ia esquecendo… se você gostou do artigo compartilhe com seus amigos, grupos e redes sociais, nos ajude a divulgar conhecimento com a galera da área de Infra de Redes.
E se você tem alguma dúvida, comentário ou até mesmo um elogio utilize o campo de comentários que tem descendo a página!
Olá meu caro aluno, amigo, visitante do blog! Hoje vou falar sobre um assunto que entrou na nova versão do CCNA, o Cisco CCNA 200-301, que são os Tipos de Fibra Óptica que podemos encontrar em uma Rede Corporativa.
Portanto, se você está pensando em fazer o CCNA 200-301 ou precisa aprender mais sobre os tipos de fibra óptica para utilizar no seu dia a dia você está no lugar certo!
O que é uma Fibra Óptica?
A fibra óptica pode ser representada como um tubo flexível de vidro onde a luz se propaga.
Essa é uma representação básica da fibra óptica.
Esse tubo é chamado de núcleo e, portanto, é o meio onde a luz se propaga.
O núcleo é coberto com uma casca que tem a função de proteger e garantir que a luz fique confinada dentro do núcleo.
A casca, por sua vez, também é coberta por um revestimento de proteção.
Na prática os cabos possuem diversos revestimentos de proteção conforme a sua aplicação.
Tipos de Fibra Óptica
Você vai ver que existem diversos tipos de fibras ópticas e abaixo temos a representação dos diâmetros típicos de fibras do tipo multimodo e monomodo.
A luz de um LED ou um laser é colocada na ponta do núcleo e então ocorre a propagação até o destino.
A forma com que a luz se propaga no núcleo é o objeto de estudo da óptica, assim como os tipos de fibra óptica.
A lei de snell, os conceitos de refração e dispersão são aplicados diretamente na tecnologia de fabricação das fibras.
Isso faz toda a diferença na hora de projetar e dimensionar um sistema de comunicações ópticas, pois dependendo da distância e uso da fibra óptica podemos baratear ou onerar um projeto de rede.
As Fibras ópticas ser divididas em 2 grupos:
Fibras Multimodo
Fibras Monomodo.
As Fibras multimodo podem ser de índice degrau ou índice gradual.
Fibras Ópticas Multimodo
Imagine uma fibra óptica com
um laser na ponta como na figura a seguir.
Observe que a luz que sai do laser
se propaga de vários modos:
Um feixe (f1) sai
da parte de baixo do laser e reflete na parte de cima do núcleo da fibra óptica
e vai se propagando em zigue-zague até o destino.
Um segundo feixe
(f2) sai da parte do meio do laser e se propaga em linha reta na fibra óptica
até chegar do outro lado da fibra.
E finalmente, um
feixe (f3), sai da parte de cima do laser e reflete na parte de baixo do núcleo
da fibra óptica e vai se propagando em zigue-zague até a outra extremidade.
Como esses 3 feixes, “n” feixes saem do laser resultando em “n” modos de propagação, portanto, dentre os tipos de fibra óptica, aquela que proporciona esse tipo de propagação é chamada de fibra multimodo.
As fibras multimodo foram as primeiras a surgir e possuem um núcleo maior que as fibras monomodo, o que resulta nos “n” modos de propagação.
Como elas são menos “exigentes” no modo que a luz se propaga são também mais “baratas”, porém suportam distâncias menores que as monomodo que vamos estudar a seguir.
Fibras Ópticas Monomodo
Antes de mais nada, imaginemos uma fibra com um núcleo tão fino que quando a luz do laser é acoplada, o feixe de luz transportado permite somente um modo de transmissão.
Nesse caso existe somente um caminho possível para a propagação, ou seja, somente um modo.
Entre os diversos tipos de fibra óptica, as fibras com essas características são denominadas fibras monomodo.
A fabricação de fibras ópticas monomodo é mais complexa devido à dificuldade mecânica de fibras tão finas.
Nas fibras monomodo anula-se a dispersão modal e obtém-se uma menor atenuação.
A conectividade do laser, contudo, é mais difícil o que exige que o laser utilizado seja mais preciso de alta qualidade elevando o custo de todo o sistema.
A princípio as fibras monomodo são utilizadas em sistemas de média e longas distâncias, cabos de fibras estaduais, backbones de grandes distâncias e inclusive em comunicações intercontinentais (cabos submarinos) onde há a transmissão de altas taxas de dados.
Por exemplo, podem ser utilizadas em cabos submarinos.
Onde Devo Utilizar os Tipos de Fibra Óptica Monomodo e Multimodo na prática?
A grande vantagem da fibra monomodo cabos de fibra óptica é a possibilidade de transmissão de sinais em longa distância.
Normalmente essas distâncias podem se de até 120 quilômetros sem o uso de regeneradores ópticos.
Já as fibras multimodo tem uma faixa máxima de transmissão é de cerca de 2 km.
Portanto, se sua empresa tem links internos de até 2km conectando os switches de Core, Distribuição e Acesso, as fibras monomodo podem ser utilizadas tranquilamente.
Agora, se houver necessidade de links com distâncias superiores a 2km até 120km o uso de uma fibra óptica monomodo é mais recomendado.
Então vamos finalizar o artigo sobre tipos de fibra óptica para o CCNA 200-301!
PARABÉNS para você que leu até aqui e me acompanhou até o final…
… saiba que você é raridade! Muitos desistem!
Muito obrigado e até um próximo artigo.
Ah, já ia esquecendo… se você gostou do artigo compartilhe com seus amigos, grupos e redes sociais, nos ajude a divulgar conhecimento com a galera da área de Infra de Redes.
E se você tem alguma dúvida, comentário ou até mesmo um elogio utilize o campo de comentários que tem descendo a página!
Como o Endereçamento IPv4 vai morrer em breve, segundo muitos “especialistas”, nada melhor que conhecê-lo muito bem antes que ele seja sepultado ou até mesmo cremado, certo?
Afinal, para conhecer bem algo novo nada melhor que dominar seu antecessor para entender o porque das mudanças.
Portando vou fazer uma revisão “monstra” sobre IPv4 e classes nesse artigo de hoje para fazer com que nossos leitores, alunos, amigos e seguidores “dominem” a arte de trabalhar com esse protocolo que nos acompanha a tantos anos!
Deu até uma pontinha de nostalgia e saudades (rsrs)… #soquenao
Introdução ao Endereçamento IPv4
A camada de Internet no TCP/IP, é responsável pelo endereçamento lógico e escolha do melhor caminho entre as redes.
O endereço IP versão 4 ou IPv4 é um número de 32 bits escrito com quatro octetos (8 bits ou um byte) representados no formato decimal como, por exemplo, “10.0.0.1”.
Os números em cada um dos octetos em decimal podem ir de 0 a 255, portanto os endereços IP têm seu valor mais baixo em 0.0.0.0 e o mais alto em 255.255.255.255.
Os endereços IP são divididos em duas partes, onde a primeira parte do endereço identifica uma rede (conjunto de hosts) e a segunda parte identifica um host individual dentro dessa rede.
Para identificar a porção de rede e de host é utilizada uma “máscara de rede”, onde os bits 1 na máscara representam a porção de rede e os bits zero a porção de host no endereço IP.
Por exemplo, o IP anterior 10.0.0.1 com uma máscara 255.0.0.0 (11111111.00000000.00000000.00000000) tem o “10” como porção de rede e “0.0.1” como porção de host.
Resumo das Classes de Endereços IP Versão 4
No início do desenvolvimento das redes IP os endereços foram divididos em cinco classes de endereços (A, B, C, D e E), sendo que três dessas classes (A, B e C) podem ser utilizadas como endereços de host.
Veja abaixo um resumo sobre as classes de endereços IPv4:
Classe
A: Primeiro bit do primeiro octeto é 0 (zero), utiliza o primeiro
octeto para definir as redes e os três últimos para endereçar os hosts. Vão das
redes 1.0.0.0 a 126.0.0.0.
Classe
B: Primeiros dois bits do primeiro octeto são 10 (um, zero), utiliza o
primeiro e segundo octetos para definir as redes e os dois últimos para
endereçar os hosts. Vão de 128.0.0.0 a 191.255.0.0.
Classe
C: Primeiros três bits do primeiro octeto são 110 (um, um, zero),
utiliza os três primeiros octetos para definir as redes e o último para
endereçar os hosts. Vão de 192.0.0.0 a 223.255.255.0.
Classe
D: Esta classe é destinada a endereços de multicast e seus primeiros
quatro bits do primeiro octeto são 1110 (um, um, um, zero). Todos os endereços
de Multicast são endereços de Host, não existem redes com endereços de
Multicast. Sua faixa de endereçamento vai de 224.0.0.0 até 239.255.255.255.
Classe
E: Esta é uma classe de endereço especial e reservada, sendo que os
primeiros quatro bits do primeiro octeto são 1111 (um, um, um, um). Não são
utilizadas para endereçamento, atualmente está reservada a testes pela IETF.
Sua faixa de endereçamento vai de 240.0.0.0 até 255.255.255.254.
Existem também endereços IP reservados para uso especial, os mais importantes são:
A rede 0.0.0.0
é reservada para representação da Internet em rotas IP;
A rede 127.0.0.0
(127.0.0.1 até 127.255.255.255) está reservada para o endereçamento de
loopback, ou seja, se você fizer em seu computador um ping para o IP 127.0.0.1
você está pingando sua própria placa de rede;
O endereço 255.255.255.255
é reservado para o broadcast local, ou seja, um ping para esse endereço IP e
todas as redes IP (classes A, B e C) responderiam ao ping.
Origem das Classes e Problemas com o Endereçamento IPv4
No início da Internet não era prevista essa taxa de adesão tanto de empresas como do setor público em geral.
Por isso mesmo, os IP utilizados para endereçar as redes foram divididos em três classes de tamanhos fixos da seguinte forma (reforçando a informação anterior):
Classe
A: definia o bit mais significativo como 0, utilizava os 7 bits
restantes do primeiro octeto para identificar a rede, e os 24 bits restantes (3
últimos octetos) para identificar o host. Esses endereços utilizavam a faixa de
1.0.0.0 até 126.0.0.0.
Classe
B: definia os 2 bits mais significativo como 10, utilizava os 14 bits
seguintes para identificar a rede, e os 16 bits restantes (2 últimos octetos)
para identificar o host. Esses endereços utilizavam a faixa de 128.1.0.0 até
191.254.0.0.
Classe
C: definia os 3 bits mais significativo como 110, utilizava os 21 bits
seguintes para identificar a rede, e os 8 bits restantes (último octeto) para
identificar o host. Esses endereços utilizavam a faixa de 192.0.1.0 até
223.255.254.0.
Note os seguintes pontos negativos dessa divisão inicial dos
endereços IP:
A classe A atendia um número muito pequeno de
redes e ocupava metade de todos os endereços disponíveis, portando poucas redes
com muitos endereços.
A classe B ainda assim possuía um número muito
grande de hosts por rede.
A classe C permitia criar muitas redes só que
com poucos endereços disponíveis.
Ao mesmo tempo em que as classes A e B traziam
muitas vezes desperdícios de endereços IP, a classe C muitas não supria a
necessidade de endereços necessários disponíveis.
Alguns outros fatos históricos interessantes sobre o crescimento da Internet:
Em 1990 já existiam 313.000 hosts conectados à
Internet.
Em maio de 1992 38% das faixas de endereços
classe A, 43% da classe B e 2% da classe C já estavam alocados, sendo que a
rede já possuía 1.136.000 hosts conectados.
Em 1993, com a criação do protocolo HTTP e a
liberação por parte do Governo estadunidense para a utilização comercial da Internet,
a quantidade de hosts na Internet passou de 2.056.000 em 1993 para mais de
26.000.000 em 1997.
Tendo essa explosão no uso da Internet e requisições de
novos endereços IP de uma maneira muito acima da esperada, a IETF (Internet
Engineering Task Force) foi obrigada a elaborar estratégias para solucionar a
questão do esgotamento dos endereços IP e do aumento da tabela de roteamento,
pois com o crescimento do uso da Internet os roteadores também começaram a
ficar sobrecarregados.
Em novembro de 1991 é formado o grupo de trabalho ROAD (Routing and Addressing), que apresenta como solução a estes problemas, a utilização do CIDR (Classless Inter-domain Routing).
Basicamente o CIDR tem como ideia central o fim do uso das classes de endereços, por isso o nome classless ou “sem classes”, possibilitando a alocação de blocos de tamanho apropriado conforme a real necessidade de cada rede.
Endereçamento IPv4 Privativo e NAT
Outras duas técnicas que foram desenvolvidas para
desacelerar o esgotamento de IPs válidos da Internet foi a introdução dos endereços IP privados (RFC 1918) e o
uso do NAT (Network Address
Translation).
Como a maioria das empresas precisam acessar a Internet para utilizar os serviços disponibilizados na rede mundial de computadores, não é necessário que todos os seus hosts estejam com endereços válidos.
Ao invés disso foram definidos os três intervalos de endereços IP declarados como privados na RFC 1918, sendo que a única regra de utilização é que nenhum pacote contendo estes endereços pode trafegar na Internet pública, por isso o nome de privado, pois eles são de uso na Intranet.
As três faixas reservadas são:
10.0.0.0 a 10.255.255.255 /8 (16.777.216 hosts)
172.16.0.0 a 172.31.255.255 /12 (1.048.576
hosts)
192.168.0.0 a 192.168.255.255 /16 (65.536 hosts)
Mas se esses endereços não podem trafegar na Internet como um computador com esse endereço poderá acessar a Internet?
Através de uma tradução do endereço privado para um endereço público de Internet, o qual é realizado pelo NAT (Network Address Translation – Tradução de Endereço de Rede).
O NAT tem como ideia básica permitir que com um único ou poucos endereços IP, vários hosts possam trafegar na Internet.
Dentro de uma rede, cada computador recebe um endereço IP privado único, que é utilizado para o roteamento do tráfego interno, e quando ele precisa acessar a Internet uma tradução de endereço é realizada, convertendo endereços IP privados em endereços IP públicos únicos na Internet.
CIDR e IPv6
Deixa eu começar falando que o endereçamento IPv4 privativo com o NAT, mais o uso do CIDR somente adiaram o triste fim dos blocos de endereços IPv4 válidos no mundo.
Quem veio para resolver o problema em definitivo é o endereçamento IPv6.
Portanto, vamos ver melhor a abordagem mais atual que não leva em consideração as classes, essa abordagem é chamada de roteamento classless (sem classe) ou CIDR (Classless Inter-Domain Routing).
O roteamento classless visa a melhor utilização de todas as faixas de IP e prolongar o uso do IPv4, pois justamente devido ao esgotamento do IPv4 é que veio a necessidade da criação de uma nova versão de endereçamento IP, o IPv6.
A versão 6 dos endereços IP ou IPv6 utiliza um número de 128 bits ao invés de 32 como no IPv4.
Outra diferença é que o IPv6 é composto por oito blocos de quatro algarismos em hexadecimal e não mais em decimal, ou seja, utiliza dos algarismos de 0 a 9 e A a F (A-10, B-11, C-12, D-13, E-14, F-15).
Para se ter uma ideia da diferença numérica entre o IPv6 e o IPv4, no IPv4 temos um endereço de 32 bits, o que nos dá 2 elevado a 32 endereços, ou seja, 4.294.967.296 mais de quatro bilhões de endereços IP.
No IPv6 temos 2 elevado a 128 possíveis endereços, ou seja, 340.282.366.920 seguido por mais 27 casas decimais, ou seja, 340 bilhões multiplicados por 10 elevado a 27 endereços IP versão 6!
Então vamos finalizar o artigo com a revisão sobre endereçamento IPv4!
Parabéns se você leu até aqui e me acompanhou até o final…
… saiba que você está de parabéns por isso!
Muito obrigado e até um próximo artigo.
Ah, já ia esquecendo… se você gostou do artigo compartilhe com seus amigos, grupos e redes sociais, nos ajude a divulgar conhecimento com a galera da área de Infra de Redes.
E se você tem alguma dúvida, comentário ou até mesmo um elogio utilize o campo de comentários que tem descendo a página!
No Windows o IPv6 já vem habilitado por padrão utilizando o SLAAC ou DHCPv6 como modo de atribuição dinâmica de seu endereçamento IPv6 local.
Normalmente se os hosts devem utilizar o SLAAC ou DHCPv6 é configurado no roteador e repassado via mensagens de RA através dos bits M e O.
O bit M em “1” significa que o host deve utilizar um servidor DHCPv6 Statefull para atribuir seu endereço local.
Já o bit O setado é utilizado em conjunto com o SLAAC para indicar ao host que ele deve pegar informações adicionais, tal como o DNS, de um servidor DHCPv6 Stateless.
Verificando o Endereçamento IPv6 no Windows
Uma vantagem do Windows é que podemos configurar os endereços IPv6 das interfaces através da Central de Rede e Compartilhamento de forma gráfica, assim como para o IPv4, porém os comandos netsh também podem ser utilizados no prompt de comando.
Veja abaixo a saída do comando ipconfig /all de um computador com Windows como sistema operacoional conectado a um roteador da Cisco sem o prefixo IPv6 global estar configurado.
Com a saída acima você vai notar um detalhe, o endereço IPv6 de link local não está utilizando o padrão EUI-64, pois se estivesse utilizando o endereço seria FE80::C218:85E5:EEDB, uma vez que o MAC da placa de rede sem fio é C0-18-85-E5-EE-DB.
Já o %20 representa ainda a interface que esse link local está configurado, você pode ver os índices das interfaces com o comando “netsh interface ipv6 show interfaces”.
Veja saída a seguir confirmando que a conexão de rede sem fio tem o índice (Ind) 20.
Privacy Extension e EUI-64
Voltando ao IPv6 de link local não utilizar o EUI-64, isso se deve porque o Windows utiliza seu endereçamento com base na RFC 3041.
Essa mesma RFC foi mais tarde atualizada na RFC 4941, chamada “Privacy Extensions for Stateless Address Autoconfiguration in IPv6”.
Essa RFC ao invés de utilizar o MAC diretamente exposto no endereço de link local, utiliza um hash MD5 para esconder o endereço físico do host.
Essa RFC trata da privacidade do host, pois se seu MAC é mostrado em seu endereço fica fácil descobrir qual seu endereço global unicast EUI-64 ou fazer ataques de camada 2.
Essa mesma técnica é utilizada para esconder os endereços
IPv6 de unicast global, veja a saída do comando abaixo após o host pegar via
SLAAC seu prefixo para autoconfiguração.
Esses endereços temporários tem um tempo de vida e são trocados por padrão a cada 7 dias.
Com o comando “netsh interface ipv6 show privacy” podemos ver essas configurações conforme saída mostrada na sequência.
Note na saída que os endereços temporários estão habilitados e com um tempo de vida máximo de 7 dias, além disso, a detecção de endereços duplicados (DAD) está ativa para eles.
Os endereços temporários dão privacidade aos hosts, porém acabam dificultando o gerenciamento da rede.
Por isso muitas vezes eles precisam ser desabilitados, fazendo com que a placa de rede utilize o padrão de interface-ID via EUI-64.
Desabilitando o Endereçamento IPv6 Temporário no Windows
Para fazer essa configuração utilize os comandos abaixo (não utilize no seu computador!):
netsh
interface ipv6 set global randomizeidentifiers=disabled
netsh
interface ipv6 set privacy state=disabled
Note na saída do ipconfig /all após a aplicação dos comandos
e desativação/ativação da conexão de rede sem fio abaixo, verificando que agora
os interface-IDs estão conforme o EUI-64.
Essa configuração é recomendada quando estamos fazendo
testes em laboratório, pois fica mais simples a identificação dos hosts.
Verificando a Tabela de Vizinhos IPv6 no Windows
Uma vez configurado o IPv6 podemos utilizar o comando “netsh interface ipv6 show neighbors” para verificar a tabela de vizinhança do IPv6.
A tabela de vizinhança no IPv6 montada com as mensagens de NA e NS do protocolo de descoberta de vizinhos (NDP).
Esse comando é equivalente ao “arp –a” utilizado no IPv4, porém lembre-se que no IPv6 não existe mais ARP, pois não existe mais suporte ao broadcast!
A resolução de endereços de camada-2 foi incorporada pelo ICMPv6, mais especificamente pelo NDP (Neighbor Discovery Protocol).
Veja saída a seguir com um exemplo da tabela de vizinhos NDP.
Informações Extras sobre o Endereçamento IPv6 no Windows
Por padrão o Windows dará preferência ao IPv6 em relação ao IPv4.
Por exemplo, se você tiver os dois protocolos configurados, onde ambos tem DNSs configurados e você digita http://www.dltec.com.br no seu browser, por padrão o sistema operacional irá utilizar a interface IPv6 e, caso via IPv6 esse nome não seja resolvido, o IPv4 será utilizado.
A Microsoft não recomenda desabilitar o endereçamento IPv6 no Windows ou mudar essas preferências.
Porém, se você não for implementar e utilizar em sua rede doméstica ou corporativa e desejar que o IPv6 seja desativado, saiba que isso é possível.
Recomendações de Vídeos sobre Endereçamento IPv6
Se você quer aprender mais ou tem dúvidas sobre os tipos de endereços IPv6, recomendamos os abaixo que estão em nosso canal do Youtube e noBlog da DlteC do Brasil:
Olá amigos, leitores do blog e alunos da DlteC! Nesse artigo vamos fazer uma introdução ao mundo do First Hop Redundancy Protocol ou FHRP.
Mas o que é redundância no primeiro salto? Ou seja, no “First Hop” que faz parte da sigla FHRP?
O primeiro salto ou first hop (FH da sigla FHRP) é a conexão entre um host (computador ou endpoint) ao seu gateway padrão, o qual aponta para as demais redes locais e remotas da empresa, inclusive aponta o caminho para a saída de Internet.
Se você já configurou um computador sabe que o gateway é um dos parâmetros que temos que inserir na configuração do IP e normalmente colocamos apenas um endereço de gateway, aí vem a pergunta:
“E se esse gateway for desligado ou ficar indisponível por qualquer motivo que seja, o que acontece?”
Simples, seu usuário fica apenas com conexão local, sem poder acessar a Internet ou outras redes da Intranet.
Por isso existem os protocolos de redundância de primeiro salto, para garantir backup do seu gateway de forma simplificada, pois esses protocolos configuram um endereço apenas em diversos gateways que se comunicam através de protocolos específicos para verificar a disponibilidade uns dos outros, caso um gateway fique indisponível o reserva assume de forma transparente para o usuário, pois eles usam um mesmo endereço de rede, um endereço IP virtual.
Existem atualmente três opções de FHRP atualmente disponibilizados em equipamentos Cisco: HSRP (Hot Standby Router Protocol), VRRP (Virtual Router Redundancy Protocol) e GLBP (Gateway Load Balancing Protocol).
Abaixo segue um quadro comparativo entre esses protocolos.
HSRP
VRRP
GLBP
RFC
RFC2281 (Cisco)
RFC3768 (Aberto)
N/A (Cisco)
Suporte a Load Balancing
Não
Não
Sim
Camada do modelo OSI
Layer-3
Layer-3
Layer-2
Protocolo de Transporte
UDP 1985
IP 112
UDP 3222
Temporizador de Hello
3 segundos
1 segundo
3 segundos
Grupo de Multicast
224.0.0.2
224.0.0.18
224.0.0.102
Formato do Mac Virtual
0000.0c07.acxx
0000.5e00.01xx
0007.b4xx.xxxx
Suporte a IPv6
Sim
Não
Sim
Abaixo segue um resumo dos três protocolos:
HSRP (Hot Standby Router Protocol Cisco): protocolo definido pela Cisco, trabalha com um roteador ativo e outro em standby (Active/standby). Permite balanceamento de cargas por sub-rede.
VRRP (Virtual Router Redundancy Protocol): protocolo aberto definido pela IETF (RFC 5798), assim como HSRP um dos roteadores ficará ativo e os demais em standby (Active/standby). Permite balanceamento de cargas por sub-rede.
GLBP (Gateway Load Balancing Protocol): protocolo definido pela Cisco, permite que ambos os roteadores trabalhem simultaneamente (ativo/ativo – Active/active). Permite balanceamento de cargas por host.
A diferença básica entre esses protocolos é que tanto o HSRP quanto o VRRP procuram apenas proteger o endereço do gateway dos hosts colocando um roteador como principal e os demais como stand-by.
Isso quer dizer que o roteador ou switch L3 stand-by não faz nada, fica apenas aguardando o principal cair para assumir o papel de gateway da rede ou sub-rede.
Já no GLBP temos TODOS os roteadores atuando na distribuição dos pacotes, pois ele faz o balanceamento de cargas entre os diversos gateways configurados.
O GLBP faz com que todos os roteadores fiquem ativos, diferente do HSRP e VRRP que tem apenas o roteador principal como ativo e os demais ficam em modo stand-by.
Espero que você tenha gostado do artigo sobre FHRP, vou trazer nas próximas publicações um pouco mais sobre cada um dos protocolos separadamente.
Qualquer dúvida, elogio ou sugestão é só utilizar a área de comentários que fica descendo a página, nós vamos ler e responder a todos com o maior carinho!