A Cisco anunciou dia 10 de junho de 2019 durante o Cisco Live San Diego a mudança no seu programa de certificações, o quem tem gerado muita confusão e dúvidas na cabeça de quem está na trilha de uma certificação Cisco.
Nesse artigo vou tentar esclarecer boa parte dessas dúvidas e se ficar algo de fora ou algo que você não encontrou no artigo que “te preocupa”, basta utilizar o campo de comentários que fica no final do artigo que vamos ajudar (mesmo que você não seja nosso aluno)! Combinado?
Abaixo seguem os tópicos que serão abordados nesse artigo:
- Informações Gerais Sobre as Novas Certificações Cisco
- Preços e Idiomas das Novas Certificações Cisco
- Níveis de Certificação Cisco (a Famosa Pirâmide)
- Mudanças nas Certificações Cisco de Entrada ou Entry Level
- Alterações no Nível Associate – CCNA
- O que Vai Cair no Novo CCNA 200-301?
- Nível de Especialista ou Specialist
- Mudanças no Nível Professional – CCNP
- Mudanças no nível Expert – CCIE
- Mudanças no Nível Arquiteto – CCAr
- Recertificação
- Próximos Passos e Recomendações sobre “O que Fazer?”
- Recomendações para Alunos da DlteC
Tenha uma ótima leitura e lembre-se que você pode usar o campo de comentários para deixar suas dúvidas, sugestões ou seu elogio!
Informações Gerais Sobre as Novas Certificações Cisco
As novas certificações só entram em vigor na data de 24 de fevereiro de 2020, sendo que as certificações atuais poderão ser realizadas até 23 de fevereiro de 2020.
Após a data do dia 24/02/2020 somente as provas novas estarão disponíveis.
Outro ponto interessante é que dessa vez as novas provas não podem ser realizadas ANTES de 24/02/2020!
Qual o PORQUE dessas alterações nas certificações Cisco para 2020?
A Cisco justificou que essas mudanças visam a melhoria contínua do processo de certificação, assim como ajustes nas trilhas e tópicos de estudo para adequação com o novo modelo de Redes que está nascendo!
Uma rede muito mais integrada, flexível e com possibilidades infinitas de conexão.
Preços e Idiomas das Novas Certificações Cisco
Ah, antes que você pergunte ainda não foram divulgados preços das novas provas, apenas que a Cisco pretende reduzir o custo total da trilha de certificações.
Mas custo total não quer dizer individual, portanto vamos aguardar cenas dos próximos capítulos.
Outro ponto geral é sobre o IDIOMA das provas…
… a Cisco divulgou que não tem intenção de traduzir as novas certificações e a princípio ficarão os idiomas atuais: Inglês e Japonês.
Agora vamos dar continuidade em nossa leitura falando sobre os níveis de certificação!
Níveis de Certificação Cisco (a Famosa Pirâmide)
Os níveis de certificação Cisco continuam praticamente os mesmos, com a diferença que agora a Cisco evidenciou um nível de especialista (Specialist) entre os níveis Associate (CCNA) e Professional (CCNP), conforme abaixo.
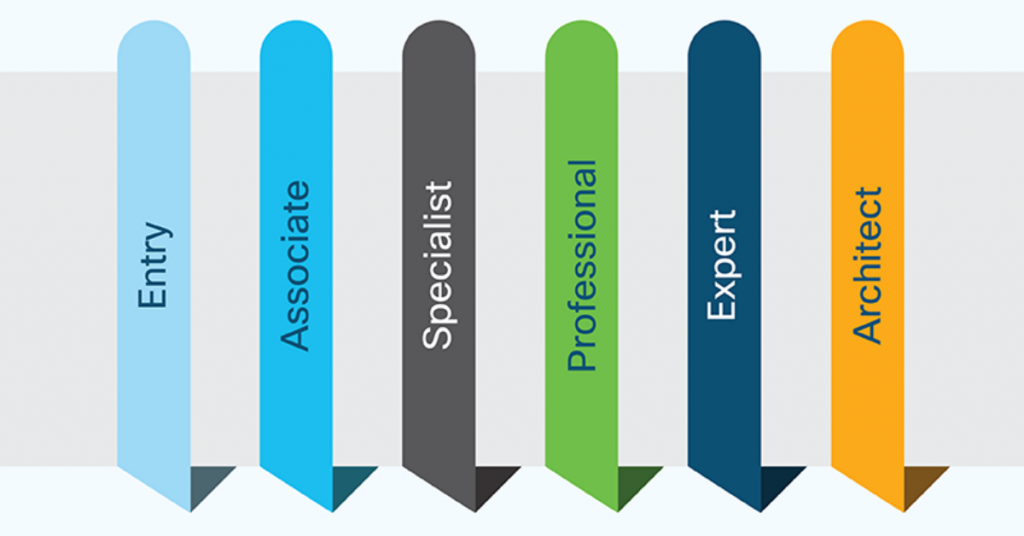
Os níveis iniciam no Entry Level ou certificações Cisco de entrada, depois passam para o nível Associate, os famosos CCNAs que agora vão ser aglutinados em uma única prova (vamos falar mais sobre o CCNA na sequência).
Após o CCNA temos a novidade que foi evidenciada que são as certificações de especialista ou Specialist.
Até o momento as certificações de especialista eram mais relevantes aos parceiros da Cisco, porém agora elas serão utilizadas para indicar as diversas especializações que um profissional pode ter durante sua trilha de certificações.
Por exemplo, um CCNP Enterprise (vamos falar mais tarde sobre os CCNPs) pode tirar sua certificação com foco em Roteamento, porém ao longo da carreira pode fazer certificações de Wireless e comprovar com um título de especialista essa habilidade extra como CCNP.
Após isso temos o nível profissional ou Professional, que são os CCNPs, logo após os Experts e por último o nível de Arquiteto de Soluções Cisco.
Vamos falar sobre as mudanças em cada nível de certificação na sequência separadamente, não se preocupe.
Outra mudança radical é que a Cisco tirou os pré-requisitos que existiam antigamente para entrada e evolução entre os níveis, ou seja, ela simplesmente RETIROU os Pré-Requisitos.
Isso mesmo… Você agora pode iniciar direto pelo CCNP sem passar pelo CCNA!
Essa mudança foi feita porque a Cisco quer agora respeitar a bagagem e o nível de conhecimento dos profissionais que estão entrando no processo de certificação Cisco, pois se você já tem os conhecimentos, por exemplo, de um CCT e CCNA pode entrar direto no CCNP, sem perder tempo ou dinheiro com a base já conhecida.
A única exceção será para o nível CCAr, o qual apenas sendo CCIE você poderá se candidatar.
Agora vamos ver o que muda em cada um dos principais níveis de certificação.
Mudanças nas Certificações Cisco de Entrada ou Entry Level
No Entry Level ou nível de entrada vamos ter uma mudança drástica, pois a certificação CCENT ou Cisco Certified Entry Networking Technician vai deixar de existir a partir de 24 de fevereiro de 2020 e as certificações de nível técnico chamadas de CCT ou Cisco Certified Technician tomarão seu lugar.
Outra informação é que os CCTs atuais serão descontinuados e novas certificações serão criadas, porém ainda não foram divulgados detalhes sobre essas novas provas.
Na prática isso significa se você tiver a certificação CCENT isolada no dia 24/02/2020 você vai simplesmente perder esse título, pois ela não tem paralelo no novo quadro de certificações, uma vez que o CCT e CCENT não serão totalmente equivalentes.
Portanto, se você é CCENT procure antes da data da virada do programa novo de certificação Cisco tirar o ICND-2 para tornar-se CCNA R&S, ou então quaisquer provas de CCNA que tenham o CCENT como pré-requisito, por exemplo, o CCNA Security.
Assim, quando vier a data da migração você será migrado para o novo CCNA (vamos falar disso a seguir).
Alterações no Nível Associate – CCNA
O nível CCNA ou Cisco Certified Network Associate passou por uma mudança radical também!
Ao invés de vários CCNAs, a partir da data da virada teremos apenas DUAS certificações no nível Associate! Vamos falar da primeira…
Agora não existirão mais CCNAs por área de tecnologia como os atuais: CCNA Cloud, CCNA Collaboration, CCNA Cyber Ops, CCNA Data Center, CCDA, CCNA Industrial, CCNA Routing and Switching, CCNA Security, CCNA Service Provider e CCNA Wireless.
Uma certificação única chamada simplesmente “CCNA” com o código 200-301, a qual terá seu material didático chamado “Implementing and Administering Cisco Solutions” substituirá TODAS as anteriores.
Portanto, se você tiver um ou mais CCNAs válidos até o dia da virada, no dia 24 de fevereiro de 2019 eles serão migrados para uma única certificação chamada CCNA e com o prazo de validade que você possui.
Por exemplo, você tirou o CCNA R&S em janeiro de 2018, ele tem uma validade de três anos e deve expirar em janeiro de 2021. No dia 24/02/2019 você passará a ser CCNA e a data de validade dele será em janeiro de 2021.
Além de migrar sua ou suas certificações para um único CCNA, a Cisco noticiou que dará um “Badge” para cada CCNA versão atual que você tenha, indicando assim suas especializações em outras tecnologias.
O que será esse badge ainda não ficou bem claro, mas atualmente ao passar em uma certificação Cisco já é fornecido o badge da certificação pela Cisco, provavelmente será algo semelhante.
Agora vamos falar sobre a segunda opção no nível Associate…
Além do CCNA também teremos a partir de fevereiro de 2020 o CCNA DevNet, focado em profissionais que trabalharão com desenvolvimento de software, pessoal de DevOPs e especialistas em automação de serviços de Rede.
São os profissionais que atuarão com APIs, desenvolvimento de aplicações, automação da Infraestrutura e demais serviços da nova geração de Redes que está se desenvolvendo.
A certificação terá o nome de DEVASC (Developing Applications and Automating Workflows using Cisco Core Platforms) e o código 200-901.
A validade dos novos CCNAs não foi alterada, ou seja, continua com 3 anos.
Como Será e o que Vai Cair no Novo CCNA 200-301?
O novo Cisco Certified Network Associate (CCNA 200-301) será uma prova de 120 minutos e para nós que não somos nativos na língua inglesa teremos ainda os 30 minutos de “prorrogação”.
Ele vai testar conhecimentos e habilidades relacionadas aos fundamentos de Redes, acesso às Redes, conectividade IP (IPv4 e IPv6), serviços IP, fundamentos de segurança, automação e “programabilidade”.
Não será exigido curso oficial da Cisco para fazer o novo CCNA, assim como já é atualmente.
Se tivesse que resumir o novo CCNA diria que ele é a base do atual CCNA R&S com algumas pitadas de Wireless, Segurança e “Pogramability” (básico de SDN e automação).
A estimativa é que o novo CCNA seja maios ou menos 25% menor que a versão atual em sua totalidade, comparando os conteúdos.
Em relação a conteúdo novo também deve entrar entre 25 a 30% de matérias realmente novas no novo CCNA 200-301.
O novo blueprint (tópicos a serem cobrados na prova) terá os seguintes itens já com seus referidos pesos para a prova de certificação CCNA 200-301:
- 1.0 Network Fundamentals – peso 20%
- 2.0 Network Access – peso 20%
- 3.0 IP Connectivity – peso 25%
- 4.0 IP Services – peso 10%
- 5.0 Security Fundamentals – peso 15%
- 6.0 Automation and Programmability – peso 10%
Entram nessa nova prova muito conteúdo do atual CCNA R&S, CCENT e ICND-2, assim como alguns tópicos do CCNA Security e CCNA Wireless.
Em termos de roteamento ficaram apenas a configuração de rotas estáticas IPv4 e IPv6, assim como a configuração do OSPFv2 (para IPv4) Single Area.
Não vai cair mais as configurações do RIPv2, EIGRP e BGP-4 nessa prova.
Outras coisas que você não vai mais ouvir falar e nem vai mais cair na nova prova do CCNA 200-301: OSI, VTP, Licenciamento e ugrades do Cisco IOS, Tecnologias WAN (serial, PPP, MPLS, Metro Ethernet…) nem APIC-EM.
Ah, continua caindo cálculo de sub-redes IPv4!
A parte de Virtualização e SDN já existiam na versão anterior do CCNA R&S, porém foram complementadas nessa nova versão de CCNA 200-301.
O que terá de novidade no novo Cisco CCNA 200-301:
- Wireless LANs
- Dynamic ARP Inspection e DHCP Snooping
- Arquiteturas de segurança
- Overlay, Underlay, Fabric e DNA Center
Agora vou dar um destaque maior nas novidades da parte de programabilidade e automação, veja os itens novos que entraram em destaque:
- 6.1 Explain how automation impacts network management
- 6.2 Compare traditional networks with controller-based networking
- 6.3 Describe controller-based and software defined architectures (overlay, underlay, and fabric)
- 6.3.a Separation of control plane and data plane
- 6.3.b North-bound and south-bound APIs.3 Describe controller-based and software defined architectures (overlay, underlay, and fabric).2 Compare traditional networks with controller-based networking.3.a Separation of control plane and data plane
- 6.4 Compare traditional campus device management with Cisco DNA Center enabled device management
- 6.5 Describe characteristics of REST-based APIs (CRUD, HTTP verbs, and data encoding)
- 6.6 Recognize the capabilities of configuration management mechanisms Puppet, Chef, and Ansible
- 6.7 Interpret JSON encoded data
Você não deve se preocupar com essa mudança se estiver estudando o atual CCNA R&S, continue seus estudos!
Nível de Especialista ou Specialist
Nesse novo programa de certificações Cisco, passando nos exames de nível Professional e Expert você receberá certificações do nível especialista ou “Cisco Certified Specialist Certifications“.
Por exemplo, passando na prova de Core (vamos explicar a seguir) do CCNP Enterprise, que será o exame 300-401 ENCOR, você já recebe a certificação chamada “Cisco Certified Specialist – Enterprise Core“.
Dessa maneira você será reconhecido a cada prova de certificação que fizer, não dependendo de finalizar uma trilha de certificação para obter um título que comprove seus conhecimentos naquela assunto.
Lembre-se que na versão atual de certificação um CCNP pode ter várias provas, porém você só obtém um título quando finalizar a trilha completa.
Por exemplo, o CCNP R&S tem as provas ROUTE, SWITCH e TSHOOT. Ao passar nas provas isoladamente você não recebe nenhuma certificação… só passando nas três provas você recebe o título de CCNP R&S.
Com o novo modelo de certificações você será reconhecido a cada passo, a cada exame que passar!
Mudanças no Nível Professional – CCNP
No CCNP também tivemos mudanças, porém agora vamos encontrar as diversas áreas de especialização que estamos acostumados com poucas alterações.
O CCNP terá as seguintes áreas de especialização:
- CCNP Enterprise: antigo CCNP Routing and Switching, CCNP Wireless e CCDP (Design) foram unificados nessa carreira de Enterprise.
- CCNP Security
- CCNP Service Provider
- CCNP Collaboration
- CCNP Data Center
- CCNP DevNet
A forma de obter a certificação CCNP será através de DUAS provas apenas, uma prova chamada “Core Exam” e outra chamada “Concentration Exam“.
A prova chamada Core cobrará o núcleo de conhecimentos daquela determinada área escolhida pelo candidato a CCNP.
Já a prova chamada Concentration Exam tem várias opções e você poderá escolher o tema que você deseja se desenvolver.
Além disso, você pode passar em mais de um concentration exam e ir ganhando títulos de especialista, conforme explicado anteriormente, para mostrar que você está indo além do CCNP, o que é ótimo!
Vamos a um exemplo com o CCNP Enterprise…
O core exam dele é a certificação 300-401 ou ENCOR (Implementing and Operating Cisco Enterprise Network Core Technologies).
Os concentrations exams podem ser os listados abaixo e para ser CCNP você precisa escolher apenas UM deles:
- 300-410 – ENARSI (Implementing Cisco Enterprise Advanced R-ting and Services)
- 300-415 – ENSDWI (Implementing Cisco SD-WAN Solutions)
- 300-420 – ENSLD (Designing Cisco Enterprise Networks)
- 300-425 – ENWLSD (Designing Cisco Enterprise Wireless Networks)
- 300-430 – ENWLSI (Implementing Cisco Enterprise Wireless Networks)
- 300-435 – ENAUTO (Automating and Programming Cisco Enterprise Solutions)
Veja que dentro do CCNP Enterprise você pode se especializar em Roteamento Avançado, Wireless, Design e Automação/Programação.
O prazo de validade continuará de TRÊS ANOS, porém as opções de migração entre o CCNP atual e o novo varia um pouco mais que para o CCNA.
Para isso a Cisco criou páginas de migração onde você pode ver o seu caso em específico, pois você pode ser CCNP completo ou então ter tirado uma ou mais provas da trilha do nível Professional.
Por exemplo, para o CCNP R&S que será substituído pelo CCNP Enterprise.
Se você for CCNP R&S completo na data da virada, simplesmente receberá a certificação CCNP Enterprise.
Se você passou nas provas isoladas do ROUTE e/ou SWITCH terá que fazer o ENCOR e uma prova de Concentration, ou seja, não ajuda nada!
Se você tiver as provas do ROUTE e SWITCH válidas e só falta o TSHOOT, basta fazer um concentration exam para virar CCNP Enterprise.
Agora se você tiver passado no TSHOOT apenas, basta fazer o ENCOR para tornar-se CCNP Enterprise.
Mudanças no nível Expert – CCIE
O nível Expert terá agora as seguintes carreiras:
- CCIE Enterprise Infrastructure (antigo CCIE R&S)
- CCIE Enterprise Wireless (antigo CCIE Wireless)
- CCIE Collaboration
- CCIE Data Center
- CCIE Security
- CCIE Service Provider
- CCDE (Cisco Certified Design Expert)
A forma de obtenção do título de CCIE continua a mesma, ou seja, com uma prova escrita (Written Exam) e uma de laboratório (Lab Exam).
O “CCIE Emeritus” que era obtido após 10 anos após a mudança de fev de 2020 poderá ser obtido somente após 20 anos de certificação.
Além disso, a recertificação do CCIE passou de DOIS para TRÊS anos, assim como o status chamado “CCIE Suspended” não existirá mais após a virada em fev de 2020.
Mudanças no Nível Arquiteto – CCAr
Não houveram mudanças e o Cisco Certified Design Expert continua sendo o pré-requisito para o CCAr.
Recertificação
Agora todos os exames terão validade de TRÊS anos e podem ser recertificados através da realização de outros exames de certificação ou então utilizando créditos do Continuing Education, o qual será divulgado provavelmente a partir de julho desse ano.
Para recertificação com créditos o candidato precisará de:
- 30 créditos para o CCNA
- 80 créditos para o CCNP
- 120 créditos para o CCIE
Próximos Passos e Recomendações sobre “O que Fazer?”
Eu estou escrevendo esse artigo logo após a notícia da Cisco sobre as mudanças em 2020, portanto dependendo de quando você está lendo os prazos para você podem estar mais apertados.
Para quem pegou no início ainda tem praticamente OITO MESES até a data da virada e isso dá um bom tempo de planejamento, pois SÓ EXISTEM DUAS OPÇÕES:
- Continuar os estudos e tirar sua certificação antes de 23 de fev de 2020 ou
- Para TUDO e aguardar a Cisco ou os produtores de conteúdo como nós da DlteC lançarmos novos materiais de estudo e fazer as provas novas somente a partir do dia 24 de fev de 2020.
Como haverá equivalência entre CCNAs, CCNPs e CCIEs antigos com os novos, se você tem condições de tirar sua certificação completa antes da data da virada, CORRA ATRÁS porque vai valer a pena.
Depois você pode complementar seus estudos com assuntos novos utilizando cursos e quem sabe pode até tirar outras certificações de especialista para complementar seu currículo.
O que NÃO DÁ PARA FAZER é FICAR TRAVADO por causa da mudança, afinal o mercado não vai parar e esperar dia 24 de fev do ano que vem para contratar!
O QUE NÃO VALE A PENA FAZER AGORA?
- Prova isolada do CCENT
- Ser CCNA e tirar uma nova certificação CCNA (por exemplo, ser CCNA R&S e tirar o Security)
- Passar em prova isolada do CCNP sem verificar a ferramenta de migração da Cisco, por exemplo, somente o CCNP ROUTE não vale a pena tirar. Porém verifique o Migration Tools de cada CCNP porque pode haver caso que valha a pena.
- Parar tudo e ficar esperando!
Recomendações para Alunos da DlteC
Se você é nossa aluno Premium e está nos cursos CCNA CCENT, CCNA ICND-2, CCNA Security ou algum do CCNP R&S preste atenção nessas recomendações que estou passando em nossos grupos e listas de alunos!
Vale a pena tirar somente o CCENT até a virada?
Não, somente com o CCENT você não terá nenhuma certificação mais após a virada de fev de 2020. Você precisa também tirar ou o ICND-2 ou o CCNA Security para ter o título de CCNA e ser migrado para o novo CCNA.
Já sou CCNA R&S, vale a pena tirar a certificação do CCNA Security até a virada?
Somente vale a pena se você precisa recertificar seu CCNA R&S atual, senão não vale a pena fazer a certificação, pois não importa quantos CCNAs você tenha após fev de 2020 vai virar uma certificação única.
Mas claro, se você está estudando o conteúdo vale a pena finalizar e ter o certificado para comprovar seu conhecimento no currículo.
Não vou conseguir marcar meu CCNA R&S até a virada em fev de 2020, o que devo fazer? Paro tudo e aguardo o novo material ou continuo estudando?
Continue estudando para o CCNA R&S atual através dos cursos CCNA CCENT e CCNA ICND-2. O conteúdo prova nova será em sua maioria assuntos cobrados na versão atual de prova, portanto você não vai perder nada continuando seus estudos.
Os cursos da DlteC serão atualizados para a nova versão? CCNA R&S para o novo CCNA e CCNP R&S para CCNP Enterprise?
Com certeza iremos atualizar ambos os cursos para o novo modelo antes da data da virada em fev de 2020.
Sobre o CCNP R&S o que eu devo fazer se não tenho ele completo?
Você precisa ter as provas do ROUTE e SWITCH ou o TSHOOT isolado para ter alguma vantagem na migração. O ideal é que você tire seu CCNP até lá para ser migrado para o novo CCNP Enterprise.
Se restou alguma dúvida utilizem o campo de comentários para fazer suas perguntas, estaremos aqui para ajudar da melhor maneira possível!
Se você é nossa aluno e assinante Premium não esqueça que pode também tirar suas dúvidas em nossos grupos do Facebook ou do Telegram.
Muito obrigado e até um próximo artigo!
Confiram o artigo original publicado pela DlteC do Brasil: Entenda o que Muda nas Certificações Cisco em Fevereiro de 2020